Dataflow 模型
Dataflow 模型:是谷歌在处理无边界数据的实践中,总结的一套 SDK 级别的解决方案,其目标是做到在非有序的,无边界的海量数据上,基于事件时间进行运算,并能根据数据自身的属性进行 window 操作,同时数据处理过程的正确性,延迟,代价可根据需求进行灵活的调整配置。
DataFlow 模型核心
和 Spark 通过 micro batch 模型来处理 Streaming 场景的出发点不同,Dataflow 认为 batch 的处理模式只是 streaming 处理模式的一个子集。在无边界数据集的处理过程中,要及时产出数据结果,无限等待显然是不可能的,所以必然需要对要处理的数据划定一个窗口区间,从而对数据及时的进行分段处理和产出,而各种处理模式(stream,micro batch,session,batch),本质上,只是窗口的大小不同,窗口的划分方式不同而已。Batch 的处理模式就只是一个窗口区间涵盖了整个有边界的数据集这样的一种特例场景而已。一个设计良好的能处理无边界数据集的系统,完全能在准确性和正确性上做到和“Batch”系统一样甚至应该更好。
Dataflow 模型里强调的两个时间概念:Event time 和 Process time:
- Event time 事件时间: 就是数据真正发生的时间,比如用户浏览了一个页面,或者下了一个订单等等,这时候通常就会有一些数据会被生产出来,比如前者可能会产生一条用户的浏览日志
- Process time: 则是这条日志数据真正到达计算框架中被处理的时间点,简单的说,就是你的程序是什么时候读到这条日志的
现实情况下,由于各种原因,数据采集,传输到达处理系统的时间可能会有长短不同的延迟,在分布式应用场景环境下,不仅是延迟,数据乱序到达往往也是常态。这些问题,在有边界数据集的处理过程中往往并不存在,或者无关紧要。
但在无边界数据集中,乱序,延迟问题就显得很关键。在 Dataflow 模型中,数据的处理过程中需要解决的问题,被概括为以下 4 个方面:
- What results are being computed : 计算逻辑是什么
- Where in event time they are being computed : 计算什么时候(事件时间)的数据
- When in processing time they are materialized : 在什么时候(处理时间)进行计算/输出
- How earlier results relate to later refinements : 后续数据如何影响(修正)之前的计算结果
针对以上四个问题,提出了三个模型:
- 一个支持基于事件时间的窗口(window)模型,并提供简易的 API 接口:支持固定窗口/滑动窗口/Session(以 Key 为维度,基于事件时间连续性进行划分)等窗口模式。(解决 Where 问题)
- 一个和数据自身特性绑定的计算结果输出触发模型,并提供灵活可描述的 API 接口。(解决 when 问题)
- 一个增量更新模型,可以将数据增量更新的能力融合进上述窗口和结果触发模型中。(解决 how 问题)
三个模型
windowing
这要解决的 where 问题,即在 infinite 的数据流中,我们要处理哪部分数据。
对于unbounded data,只能基于windowing做处理。windowing 有以下三种: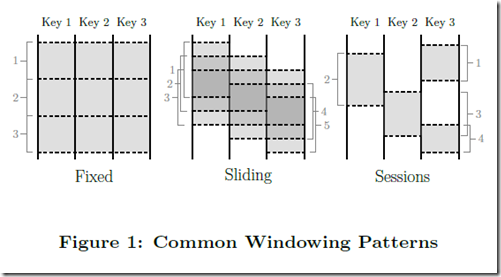
前两种很简单,Sessions Windowing,这个比较新鲜,这个是在 google 实践中很重要的一种 windowing 形式。
Session,即当连续出现 key1 时形成session windowing窗口,没有key1出现是就不存在窗口,典型应用异常检测,当出现持续异常时就是session windowing,没有异常是不需要统计Time Domains。
时间域,分为两种,
Event Time, which is the time at which the event itself actually occurred,发生时间
Processing Time, which is the time at which an event is observed at any given point during processing within the pipeline,处理时间
显然处理时间一定是晚于发生时间的,我们可以用下面的 watermark 图来 visualize 他们的 skew 关系
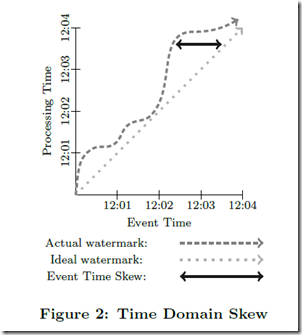
首先,dataflow 将 window 信息放入 tuple 内,
所以 dataflow 的 tuple 是 4 元组,(key; value; event time; window)
同时,支持两种 windows 操作,
AssignWindows,

可以看到通过 AssignWindows,可以将原始数据,转换为带 windowing 信息的数据
在例子给出的 case 下,一条 raw 数据会产生两条带 windowing 信息的数据
这样做的好处就将,where 信息固化在原始数据中了,你不用再在代码里面记着
问题是,这样可能会带来数据膨胀,如果 Sliding(60m,1m),岂不是一条 raw tuple,要产生 60 条带 windowing 信息的 tuple
WindowMerging,
这个过程,可以用来消除前面带来的数据膨胀,


这个过程还是比较清晰的
Triggers & Incremental Processing
开始解决 when 和 how 的问题
核心问题,我们面对的时候无序的数据,那么我们怎么知道,这个 windowing 里面的数据已经到全了,可以 emit 产生结果了?
是不是可以依赖我们上面给出的 watermark 图来预估,是可以的,但这个方案不完善,会有too fast和too slow问题。
too fast,即通过watermark你是无法保证 100% 数据完整性的,因为 watermark 是启发式生成的
too slow,即latency 问题,watermark反映的是大部分数据到全的时间点,必然不会有好的latency
所以可见,这个方案挺废的,即保证不了一致性,也保证不了latency
那么回到那个问题,我们怎么知道什么时候该 emit 结果了?
答案是,你无法准确知道。
所以这边的思路和 lamda 是一致的,先输出实时数据满足latency需要,并且用 batch数据来backfill,修正数据的正确性。
这就是这里提到的trigger 和增量更新模型,
trigger 模型解决when的问题,你可以定义各种不同的 trigger,已满足你对 latency 和 correctness 的 balancing 的需求。
增量模型解决 how 的问题,即如何修正数据的正确性,这里分为 3 种,
Discarding: Upon triggering, window contents are discarded, and later results bear no relation to previous results.
trigger 触发时,会丢弃当前 window 的数据,这样要求 various trigger fires to be independent,比如说 sum 操作
这样的好处,减小 mem 的负担;问题是,会产生碎片化数据,需要后续再次 combine 和 merge
Accumulating: Upon triggering, window contents are left intact in persistent state, and later results become a refinement of previous results.
trigger 触发时,会保留当前 window 的数据,后续可以继续 refine 数据
这样的场景,适用于 downstream consumer 支持 overwrites 操作,比如数据库
这样的问题就是,当数据量比较大的时候,你无法在 mem 里面保留长时间数据,那么需要写入存储,那么 backfill 可能需要 offline 来完成
Accumulating & Retracting: 比上面那种多了 retracting
这个只是用于不同的场景,比如 downstream consumer 是在做 sum 统计,那么必须先把上次的减去,才能加上这次的数据
DATAFLOW MODEL
In this section, we will de ne the formal model for the system and explain why its semantics are general enough to subsume the standard batch, micro-batch, and streaming models, as well as the hybrid streaming and batch semantics of the Lambda Architecture.
Core Primitives
dataflow 提供两种基本原语,分别对应于无状态和有状态
ParDo for generic parallel processing. Each input element to be processed (which itself may be a nite collection) is provided to a user-defined function (called a DoFn in Dataflow), which can yield zero or more output elements per input.
基本的无状态原语
可以等同于 flatMap,和 map 的不同是,可以输出 0 到多个结果
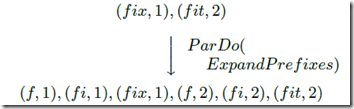
GroupByKey for key-grouping (key; value) pairs.
有状态的原语
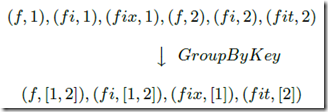
Examples
对于下面的 input,
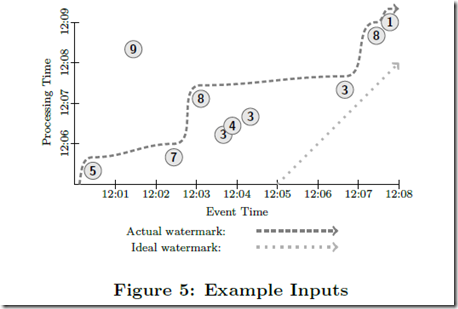
Batch Model

Batch 的方式,等所有数据都来全了,计算一遍解决,问题就是 latency 高达接近 10 分钟 (对于最早的数据)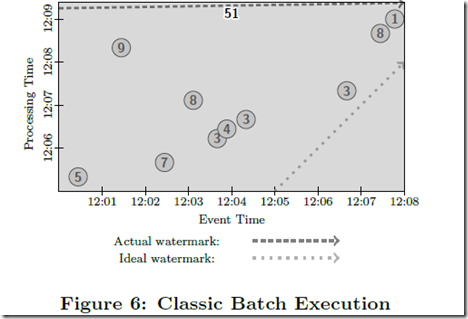
基于 windowing 的 batch 方式,和普通 batch 区别,增加 windows 聚合的结果
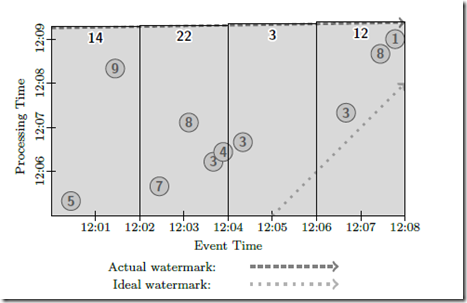
Micro-Batch Model
和 batch 比,兼顾 latency
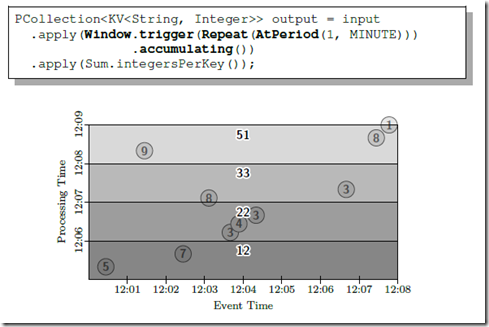
incremental 的方式不同,下面是 discarding,看看区别
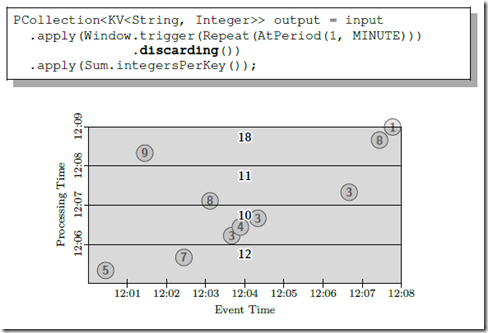
基于 windowing 的 micro-batch,
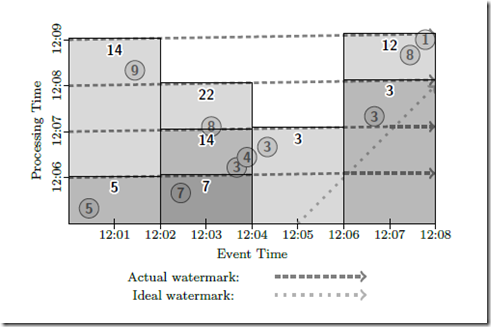
基于流的 Windowing Model
采用 watermark 的 trigger,
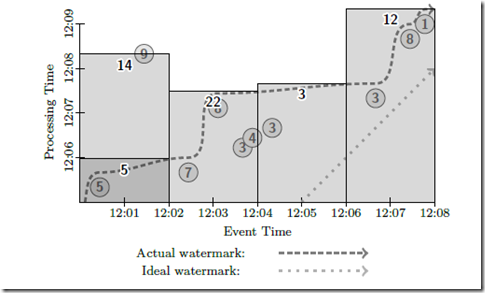
这个的问题上面说过,
too fast,9 在依据 watermark 触发时,还没到
too late, 7 的数据要等到 8 到达的时候才能输出,
在 watermark trigger 的基础上增加 micro-batch trigger,这样的好处还是提高 latency,

基于 Session Windowing Model
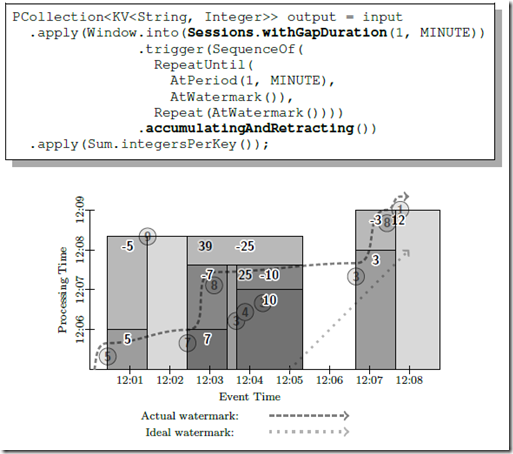
总结
更细的学习了 flink watermark 后,再来看这篇文章,就更加能懂里面的一些概念,只看文章,没有具体实现还是比较难理解它的设计要点。
参考
https://www.cnblogs.com/fxjwind/p/5124174.html
https://www.cnblogs.com/tgzhu/p/7656508.html