spark streaming
之前讲解了Google的Dataflow模型。而spark streaming是以micro batch方式来近似streaming数据进行处理。Spark Streaming从实时数据流接入数据,再将其划分为一个个小批量供后续Spark engine处理,所以实际上,Spark Streaming是按一个个小批量来处理数据流的。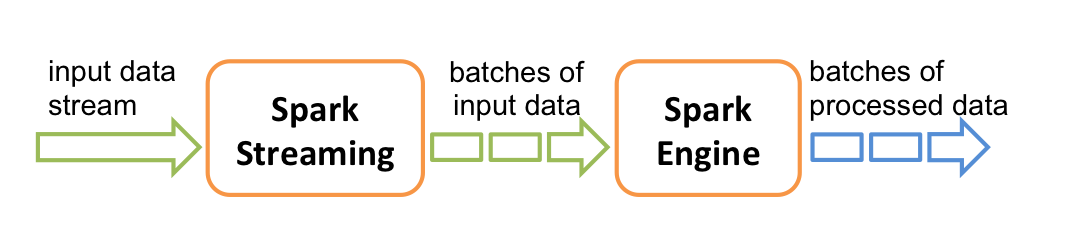
spark streaming
离散数据流(DStream)是Spark Streaming最基本的抽象。它代表了一种连续的数据流,要么从某种数据源提取数据,要么从其他数据流映射转换而来。DStream内部是由一系列连续的RDD组成的,每个RDD都是不可变、分布式的数据集。每个RDD都包含了特定时间间隔内的一批数据,如下图所示: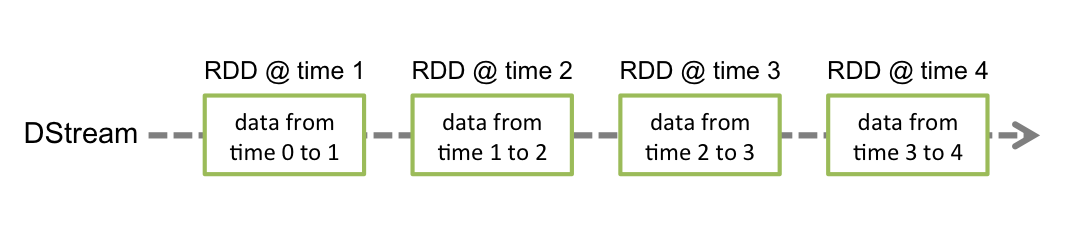
任何作用于DStream的算子,其实都会被转化为对其内部RDD的操作。例如,在代码
1 | val words = lines.flatMap(_.split(" ")) |
中,我们将lines这个DStream转成words DStream对象,其实作用于lines上的flatMap算子,会施加于lines中的每个RDD上,并生成新的对应的RDD,而这些新生成的RDD对象就组成了words这个DStream对象。其过程如下图所示:
![]()
底层的RDD转换仍然是由Spark引擎来计算。DStream的算子将这些细节隐藏了起来,并为开发者提供了更为方便的高级API。
因为底层仍是Spark引擎,所以streaming也提供了一些类似普通RDD的transform的算子。这里就不做详细介绍了,有需要的参照官网。
transform算子
transform算子能够让DStream与其他不在DStream中的数据集相计算。例如:
1 | val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information |
基于窗口(window)的算子
Spark Streaming同样也提供基于时间窗口的计算,也就是说,你可以对某一个滑动时间窗内的数据施加特定tranformation算子。如下图所示: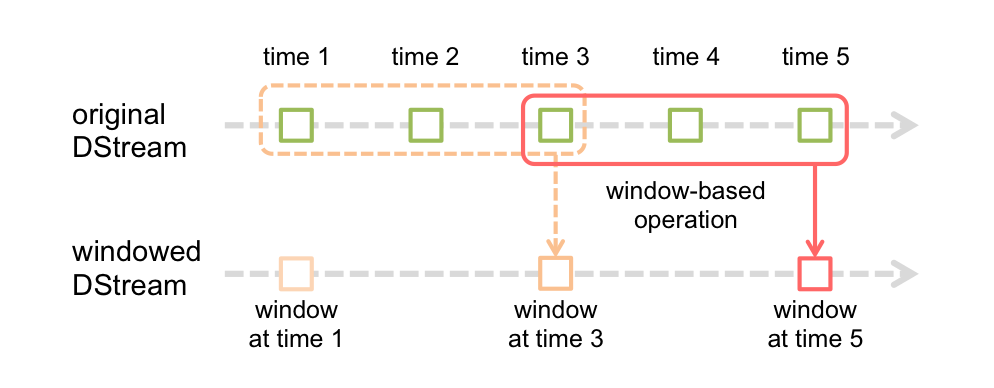
如上图所示,每次窗口滑动时,源DStream中落入窗口的RDDs就会被合并成新的windowed DStream。在上图的例子中,这个操作会施加于3个RDD单元,而滑动距离是2个RDD单元。由此可以得出任何窗口相关操作都需要指定一下两个参数:
- (窗口长度)window length – 窗口覆盖的时间长度(上图中为3)
- (滑动距离)sliding interval – 窗口启动的时间间隔(上图中为2)
注意,这两个参数都必须是DStream批次间隔(上图中为1)的整数倍。window算子
Structured Streaming
Structured Streaming是构建在Spark SQL引擎上的流式数据处理引擎,具有容错功能。你可以像在使用静态RDD数据一样来编写你的流式计算过程。当流数据连续不断的产生时,Spark SQL将会增量的,持续不断的处理这些数据并将结果更新到结果集中。你可以使用DataSet/DataFrame API来展现数据流的aggregations, event-time windows,stream-to-batch joins等操作。
Structured Streaming的核心是将流式的数据看成一张不断增加的数据库表,这种流式的数据处理模型类似于数据块处理模型,你可以把静态数据库表的一些查询操作应用在流式计算中,Spark运行这些标准的SQL查询,从不断增加的无边界表中获取数据。如图所示: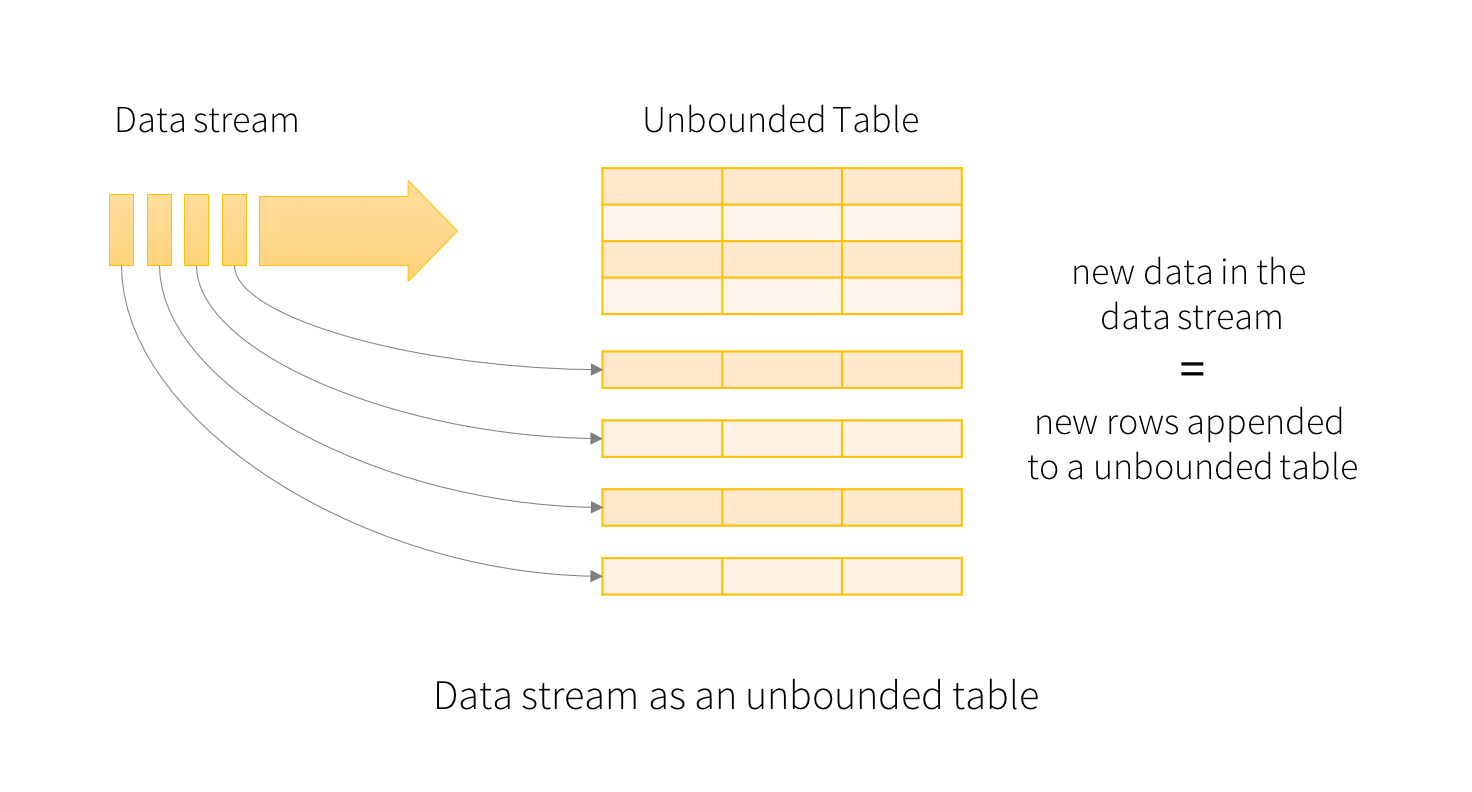
参考
http://spark.apache.org/docs/latest/streaming-programming-guide.html