CUDA学习之hello world
数据并行
当现代软件应用运行缓慢时,问题通常出在数据上——数据量太大而难以处理。图像处理应用处理包含数百万到数万亿像素的图像或视频。科学应用使用数十亿的网格点来模拟流体动力学。分子动力学应用程序必须模拟数千亿个原子之间的相互作用。航空公司排班涉及数千个航班、机组人员和机场门。这些像素、粒子、网格点、相互作用、航班等等中的大多数通常可以被独立处理。例如,在图像处理中,将彩色像素转换为灰度只需要该像素的数据。模糊图像会将每个像素的颜色与附近像素的颜色平均,只需要该小邻域像素的数据。即使是看似全局的操作,例如找到图像中所有像素的平均亮度,也可以分解为许多较小的计算,这些计算可以相互独立地执行。这种对不同数据片段的独立评估是数据并行性的基础。编写数据并行代码涉及(重新)组织计算,使其围绕数据执行,以便我们可以并行执行生成的独立计算,以更快地完成整体工作——通常快得多。
任务并行性与数据并行性 在并行编程中,数据并行性并不是唯一使用的并行性类型。任务并行性在并行编程中也被广泛使用。任务并行性通常通过对应用程序的任务分解来暴露。例如,一个简单的应用程序可能需要进行矢量加法和矩阵-矢量乘法。其中每个都将是一个任务。如果这两个任务可以独立完成,那么就存在任务并行性。I/O和数据传输也是任务的常见来源。在大型应用程序中,通常存在更多独立的任务,因此也存在更多的任务并行性。例如,在分子动力学模拟器中,自然任务列表包括振动力、旋转力、用于非键作用力的邻居识别、非键作用力、速度和位置,以及基于速度和位置的其他物理性质。
CUDA C程序结构
CUDA C通过最小的新语法和库函数将流行的ANSI C编程语言进行了扩展,使程序员能够针对包含CPU核心和大规模并行GPU的异构计算系统进行开发。顾名思义,CUDA C建立在NVIDIA的CUDA平台上。CUDA目前是最成熟的用于大规模并行计算的框架,被广泛应用于高性能计算行业,提供了在大多数常见操作系统上使用的编译器、调试器和性能分析工具等基本工具。
CUDA C程序的结构反映了计算机中主机(CPU)和一个或多个设备(GPU)的共存。每个CUDA C源文件可以包含主机代码和设备代码的混合。默认情况下,任何传统的C程序都是一个只包含主机代码的CUDA程序。可以将设备代码添加到任何源文件中。设备代码使用特殊的CUDA C关键字明确定义。设备代码包括函数或内核,其代码以数据并行方式执行。
CUDA程序的执行过程如图1所示。执行从主机代码(CPU串行代码)开始。当调用内核函数时,在设备上启动大量线程以执行内核。由内核调用启动的所有线程被集体称为一个网格。这些线程是CUDA平台中并行执行的主要工具。图1显示了两个线程网格的执行过程。我们将很快讨论这些网格是如何组织的。当一个网格的所有线程都完成执行时,该网格终止,并且执行继续在主机上,直到启动另一个网格。

图1 CUDA程序的执行
请注意,图1显示了一个简化的模型,其中CPU执行和GPU执行不重叠。许多异构计算应用程序管理重叠的CPU和GPU执行,以充分利用CPU和GPU的优势。
矢量加法内核
我们使用矢量加法来演示CUDA C程序的结构。矢量加法可以说是可能的数据并行计算中最简单的一个,是顺序编程中“Hello World”的并行等价物。在展示矢量加法的内核代码之前,先复习一下传统矢量加法(主机代码)函数的工作原理是有帮助的。下图展示了一个简单的传统C程序,包括一个主函数和一个矢量加法函数。在我们的所有示例中,每当需要区分主机和设备数据时,我们都会在主机使用的变量名称后缀“_h”,在设备使用的变量名称后缀“_d”,以提醒自己这些变量的预期用途。

图2 简单的矢量加法示例
设备全局内存和数据传输
在当前的CUDA系统中,设备通常是配有自己的动态随机访问内存(称为设备全局内存或全局内存)的硬件卡。例如,NVIDIA Volta V100配备了16GB或32GB的全局内存。将其称为“全局”内存是为了将其与程序员也可访问的其他类型的设备内存区分开。
对于矢量加法核函数,在调用核函数之前,程序员需要在设备全局内存中分配空间并将数据从主机内存传输到设备全局内存中的已分配空间。同样,在设备执行后,程序员需要将结果数据从设备全局内存传输回主机内存,并释放在设备全局内存中分配的不再需要的空间。CUDA运行时系统(通常在主机上运行)提供了应用程序编程接口(API)函数,代表程序员执行这些活动。从这一点开始,我们将简单地说数据从主机传输到设备,以简称将数据从主机内存复制到设备全局内存中。相同的情况适用于相反的方向。

图3 CUDA管理设备全局内存的API函数。
在图3中,vecAdd函数的第一部分和第三部分需要使用CUDA API函数为A、B和C分配设备全局内存;将A和B从主机传输到设备;在矢量加法后将C从设备传输到主机;以及释放A、B和C的设备全局内存。首先,我们将解释内存分配和释放函数。
cudaMalloc函数可以从主机代码中调用,为对象分配一块设备全局内存。读者应该注意cudaMalloc和标准C运行时库malloc函数之间的惊人相似之处。这是有意为之的;CUDA C是具有最小扩展的C。
cudaMalloc函数的第一个参数是一个指针变量的地址,该变量将被设置为指向已分配对象的地址。指针变量的地址应强制转换为(void *),因为该函数期望一个通用指针;内存分配函数是一个通用函数,不限于任何特定类型的对象。这个参数允许cudaMalloc函数将分配的内存的地址写入提供的指针变量,而不管其类型如何。调用核函数的主机代码将此指针值传递给需要访问已分配内存对象的核函数。cudaMalloc函数的第二个参数给出要分配的数据的大小,以字节为单位。该第二个参数的使用与C malloc函数的size参数一致。
一旦主机代码为数据对象在设备全局内存中分配了空间,它可以请求将数据从主机传输到设备。这通过调用CUDA API函数之一来完成。图4展示了这样一个API函数,cudaMemcpy。cudaMemcpy函数有四个参数。第一个参数是指向要复制的数据对象目标位置的指针。第二个参数指向源位置。第三个参数指定要复制的字节数。第四个参数指示复制涉及的内存类型:从主机到主机,从主机到设备,从设备到主机以及从设备到设备。例如,内存复制函数可用于将数据从设备全局内存中的一个位置复制到设备全局内存中的另一个位置。

图4 CUDA API函数用于主机和设备之间的数据传输
vecAdd函数调用cudaMemcpy函数将A_h和B_h向量从主机内存复制到A_d和B_d在设备内存中,然后将它们相加,并在完成相加后将C_d向量从设备内存复制到C_h在主机内存中。假设A_h、B_h、A_d、B_d和size的值已经设置好,下面是三个cudaMemcpy调用的示例。cudaMemcpyHostToDevice和cudaMemcpyDeviceToHost是CUDA编程环境中的已识别的预定义常量。请注意,通过正确排序源和目标指针并使用适当的常量进行传输类型,可以使用相同的函数在两个方向上传输数据。
1 | cudaMemcpy(A_d, A_h, size, cudaMemcpyHostToDevice); |
核函数和线程
在CUDA C中,核函数指定在并行阶段由所有线程执行的代码。由于所有这些线程执行相同的代码,CUDA C编程是众所周知的单程序多数据(SPMD)(Atallah, 1998)并行编程风格的一个实例,这是一种流行的并行计算系统编程风格。
当程序的主机代码调用核函数时,CUDA运行时系统会启动一个线程网格,该网格组织成两级层次结构。每个网格都组织成一个线程块数组,我们将其简称为块。一个网格中的所有块都是相同大小的;每个块在当前系统上最多可以包含1024个线程。
内建变量 许多编程语言都有内建变量。这些变量具有特殊的含义和目的。这些变量的值通常由运行时系统预初始化,并在程序中通常是只读的。程序员应该避免重新定义这些变量以供其他用途使用。
每个线程块中的总线程数是在调用核函数时由主机代码指定的。同一核函数可以在主机代码的不同部分以不同数量的线程调用。对于给定的线程网格,块中的线程数可以在名为blockDim的内建变量中找到。blockDim变量是一个结构,包含三个无符号整数字段(x、y和z),这些字段帮助程序员将线程组织成一维、二维或三维数组。对于一维组织,仅使用x字段。对于二维组织,使用x和y字段。对于三维结构,使用所有三个x、y和z字段。线程的组织方式通常反映数据的维度。
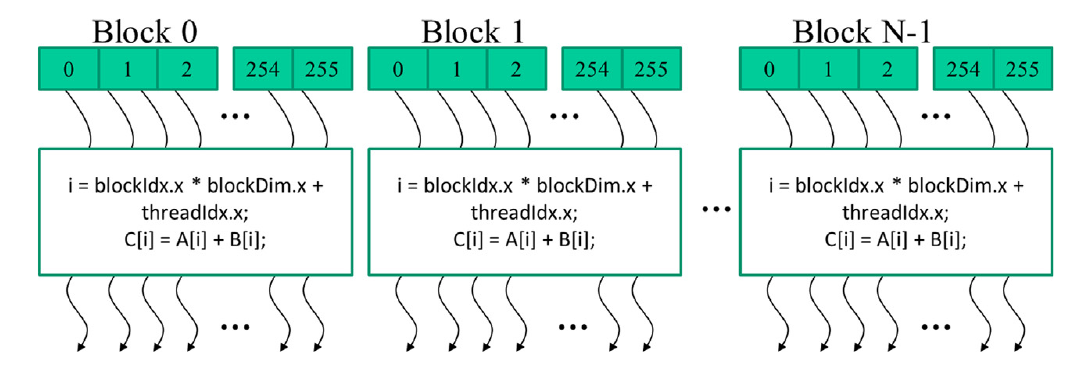
图5 所有网格中的线程执行相同的核函数代码。
CUDA核函数可以访问另外两个内建变量(threadIdx和blockIdx),这些变量允许线程彼此区分,并确定每个线程要处理的数据区域。threadIdx变量为每个线程提供块内的唯一坐标。在图5中,由于我们使用的是一维线程组织,仅使用threadIdx.x。图5中每个线程的threadIdx.x值显示在每个线程的小阴影框中。每个块中的第一个线程的threadIdx.x变量的值为0,第二个线程的值为1,第三个线程的值为2,依此类推。
blockIdx变量为块中的所有线程提供一个共同的块坐标。在图5中,第一个块中的所有线程的blockIdx.x变量的值为0,第二个线程块中的值为1,依此类推。通过与电话系统的类比,可以将threadIdx.x视为本地电话号码,将blockIdx.x视为区号。两者一起为整个国家的每条电话线提供了唯一的电话号码。同样,每个线程可以将其threadIdx和blockIdx值结合起来,为自己在整个网格内创建唯一的全局索引。
在图5中,计算了一个唯一的全局索引i,即i=blockIdx.x * blockDim.x + threadIdx.x。回顾一下,我们的示例中blockDim的值为256。块0中线程的i值范围从0到255。块1中线程的i值范围从256到511。块2中线程的i值范围从512到767。也就是说,这三个块中线程的i值形成了从0到767的连续覆盖。由于每个线程使用i来访问A、B和C,这些线程涵盖了原始循环的前768次迭代。通过启动具有更多块的网格,可以处理更大的向量。通过启动具有n个或更多线程的网格,可以处理长度为n的向量。

图6 向量加法核函数代码
调用核函数
完成了核函数的实现后,剩下的步骤是从主机代码中调用该函数以启动网格。当主机代码调用核函数时,它通过执行配置参数设置网格和线程块的维度。配置参数位于传统C函数参数之前的“<<<”和“>>>”之间。第一个配置参数给出了网格中的块数,第二个指定了每个块中的线程数。在这个例子中,每个块中有256个线程。为了确保我们有足够的线程在网格中覆盖所有的向量元素,我们需要将网格中的块数设置为所需线程数(在这种情况下为n)除以线程块大小(在这种情况下为256)的上取整(将商四舍五入为较高的整数值)。有许多执行上取整的方法。一种方法是对n/256.0应用C天花板函数。使用浮点值256.0确保我们生成一个浮点值,以便天花板函数可以正确地将其上取整。例如,如果我们要1000个线程,我们将启动ceil(1000/256.0) = 4个线程块。因此,该语句将启动4 * 256 = 1024个线程。通过核函数中的if (i , n)语句(如图2.10所示),前1000个线程将对这1000个向量元素执行加法。剩下的24个将不执行。
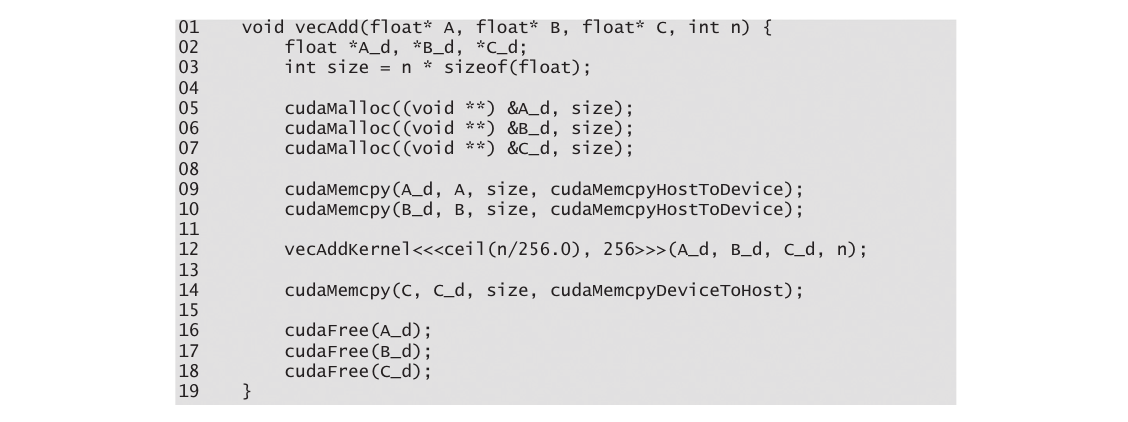
图7 矢量加法完整的host代码
编译
实现CUDA C核心需要使用多种不属于C语言的扩展。一旦这些扩展在代码中被使用,传统的C编译器就无法接受它了。代码需要由一个能够识别和理解这些扩展的编译器编译,比如NVCC(NVIDIA C编译器)。如图2.14顶部所示,NVCC编译器处理CUDA C程序,使用CUDA关键字来区分主机代码和设备代码。主机代码是纯粹的ANSI C代码,使用主机的标准C/C++编译器编译,并作为传统的CPU进程运行。带有CUDA关键字的设备代码指定了CUDA核函数及其相关的辅助函数和数据结构,由NVCC编译成称为PTX文件的虚拟二进制文件。这些PTX文件由NVCC的运行时组件进一步编译成真实的目标文件,并在支持CUDA的GPU设备上执行。
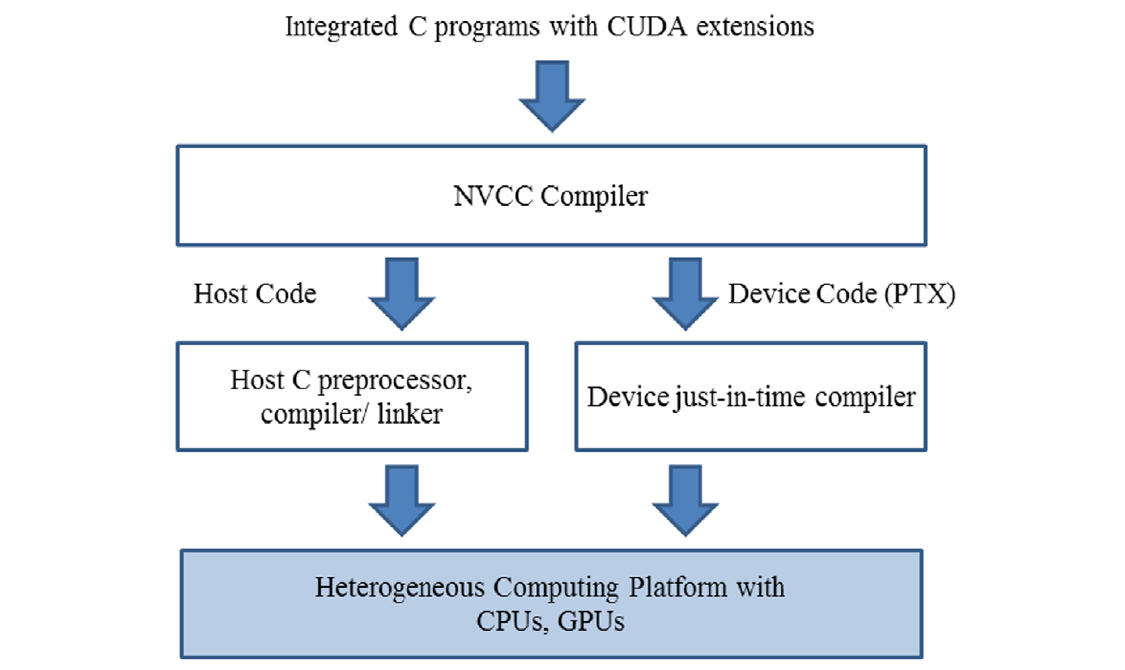
图8 CUDA C程序的编译过程概述