# =========================================================================== # batch prompts # =========================================================================== prompts = ["Hello, my name is", "The president of the United States is", "The capital of France is", "The future of AI is",]
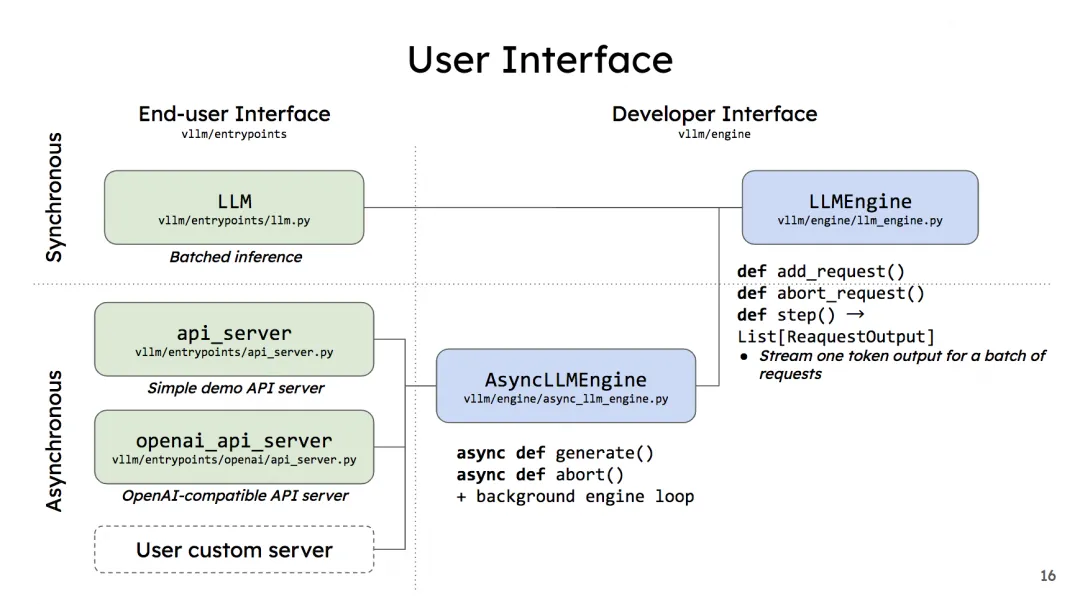
vLLM 的两种调用方式与内核引擎 LLMEngine 的关系如下(图片来自 vLLM 团队 2023 first meetup PPT):
图中左侧是用户使用界面,罗列了上述所说的两种调用方式 (注意,如前文所说,做 demo 用的 api server 官方已经不再维护了,openai_api_server 才是官方推荐的使用方式,user custom server 目前还没有实现)。右侧则是开发者界面,不难发现LLMEngine是vLLM的核心逻辑。
("To be or not to be,", SamplingParams(temperature=0.8, top_k=5, presence_penalty=0.2)),
但在其余的场景中,模型decoding的策略可能更加复杂 ,例如:
Parallel Sampling :你传给模型 1 个 prompt,希望模型基于这个这个 prompt,给出 n 种不同的 output
Beam Search :你传给模型 1 个 prompt,在采用 Beam Search 时,每个推理阶段你都会产出 top k 个 output,其中 k 被称为 Beam width(束宽)。
这些情况下,你传给模型的输入可能长下面这样:
1 2 3 4 5 6 7
# Parallel Sampling ("What is the meaning of life?", SamplingParams(n=2, temperature=0.8, top_p=0.95, frequency_penalty=0.1))
# Beam Search (best_of = 束宽) ("It is only with the heart that one can see rightly", SamplingParams(n=3, best_of=3, use_beam_search=True, temperature=0.0)),
【备注:SamplingParams 遵从 OpenAI API 范式,对其中各种参数的解释可参见 OpenAI官方文档】
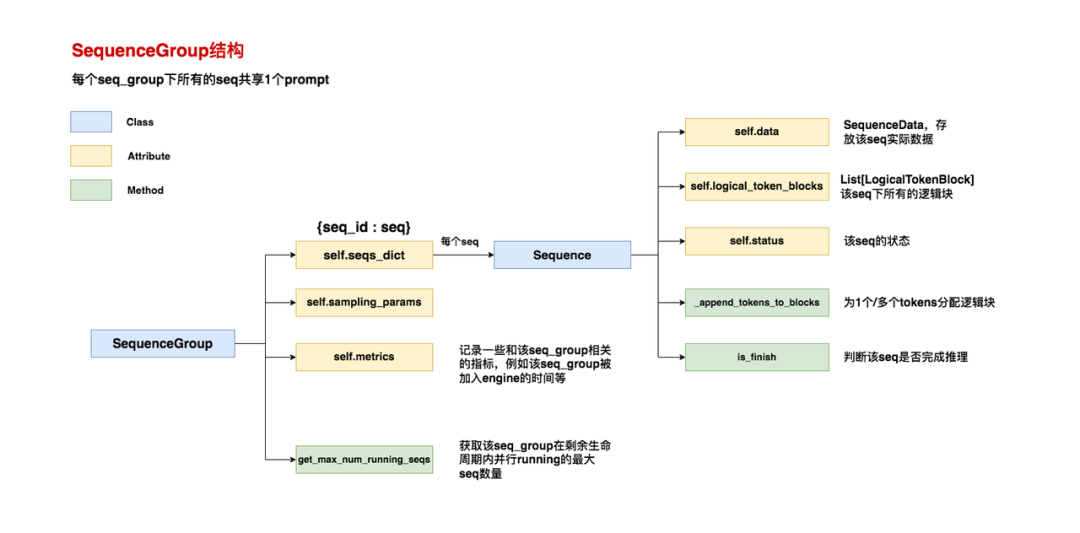
def get_max_num_running_seqs(self) -> int: """The maximum number of sequences running in parallel in the remaining lifetime of the request. 返回请求在其剩余生命周期中并行运行的最大序列数。 """ # ============================================================================ # 若采用beam search,每1个推理阶段都是best_of(束宽)个seq在running # ============================================================================ if self.sampling_params.use_beam_search: return self.sampling_params.best_of # ============================================================================ # 如果不采用beam search # ============================================================================ else: # ========================================================================= # 此时best_of默认和n一致,即表示我们希望1个prompt产出n个outputs。因此理论上,这个 # seq_group下会维护best_of个seq(这就是self.num_seqs()的返回值)。 # 如果出现best_of > self.num_seqs()的情况,说明该seq_group刚从waiting变成running # 准备做推理(参考2.2节配图中左侧第1个时刻),此时对于这个seq_group来说, # 其剩余生命周期并行运行的最大seq数量为best_of # ========================================================================= if self.sampling_params.best_of > self.num_seqs(): # At prompt stage, the sequence group is not yet filled up # and only have one sequence running. However, in the # generation stage, we will have `best_of` sequences running. return self.sampling_params.best_of # ========================================================================= # 其余时刻(例如2.2节配图中非左侧第1个时刻的所有时刻)下,我们就返回这个seq_group中 # 未完成推理的seq数量。根据2.2节介绍,我们知道一个seq的完成状态有四种: # SequenceStatus.FINISHED_STOPPED, # SequenceStatus.FINISHED_LENGTH_CAPPED, # SequenceStatus.FINISHED_ABORTED, # SequenceStatus.FINISHED_IGNORED # ========================================================================= return self.num_unfinished_seqs()
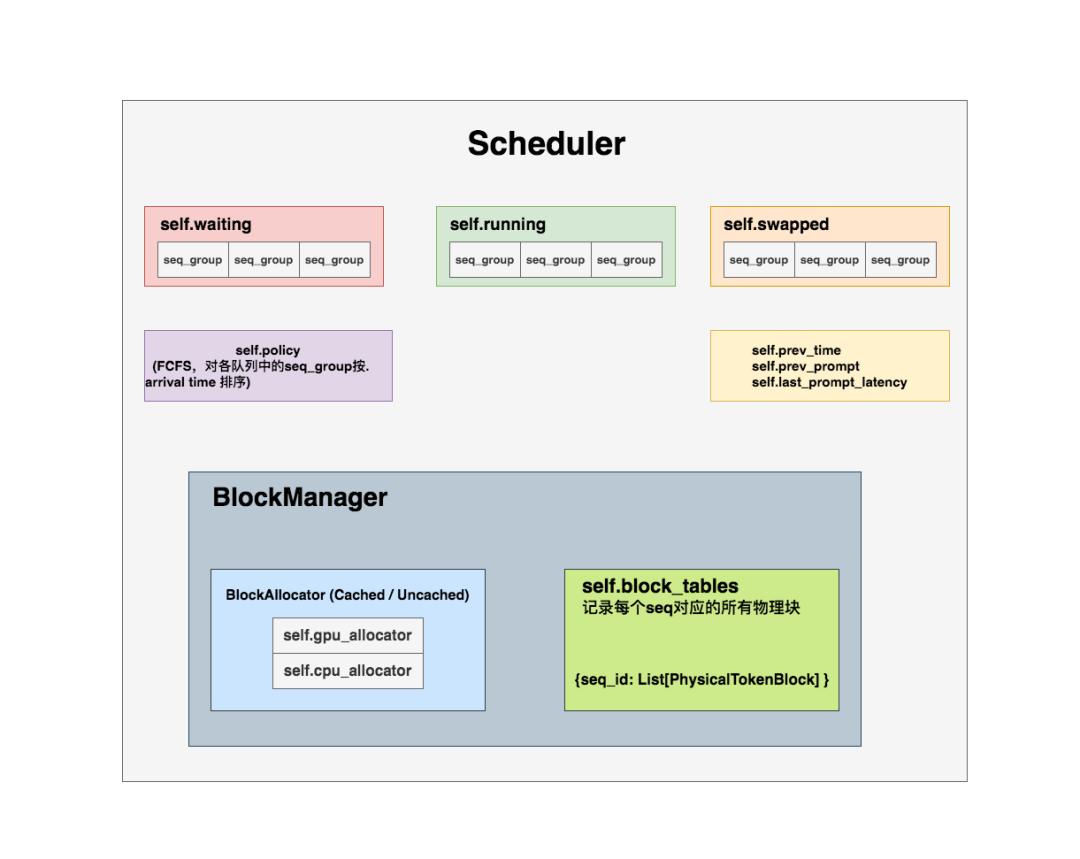
self.policy:是vLLM自定义的一个Policy实例, 目标是根据调度器总策略( FCFS ,First Come First Serve,先来先服务)原则, 对各个队列里的seq_group按照其arrival time进行排序 。相关代码比较好读,所以这里我们只概述它的作用,后续不再介绍它的代码实现。
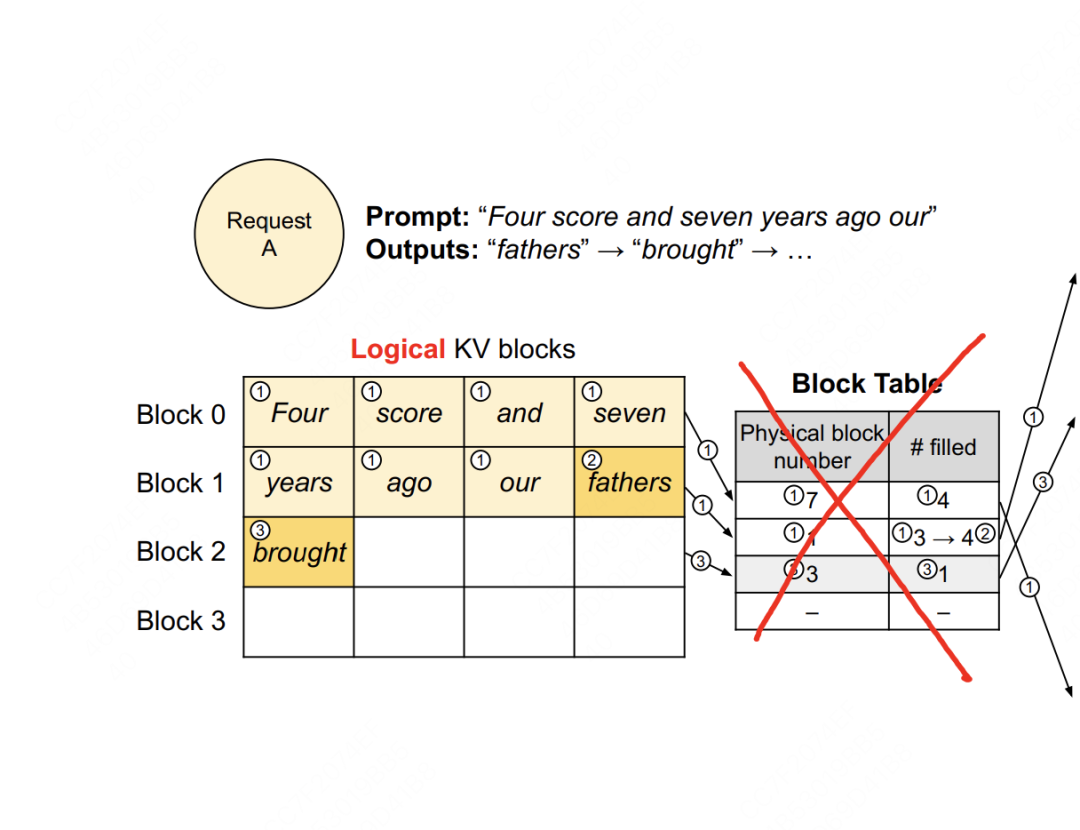
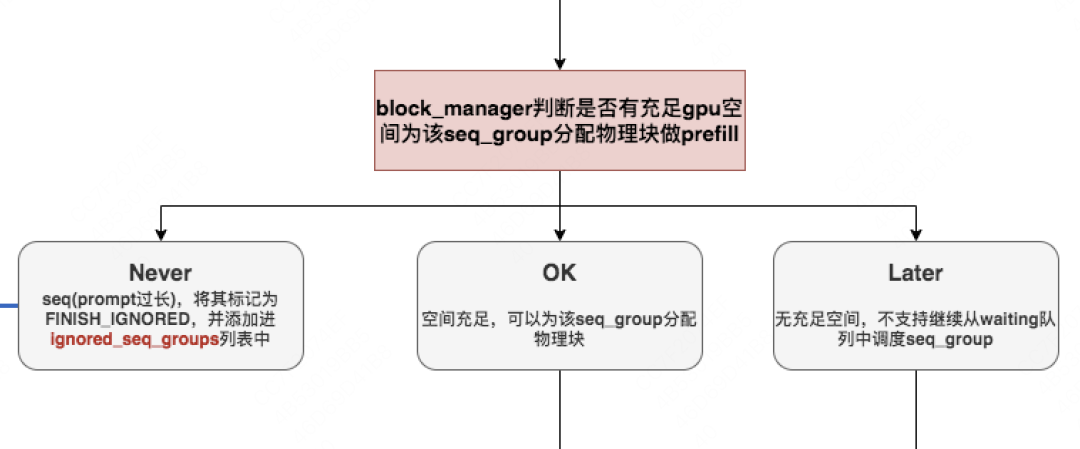
# vllm/core/block_manager_v1.py def can_allocate(self, seq_group: SequenceGroup) -> AllocStatus: """ 确实是否可以给这个seq_group分配物理块,返回结果有三种情况: - AllocStatus.NEVER:不分配; - AllocStatus.OK:可以分配; - AllocStatus.LATER:延迟分配 """ # FIXME(woosuk): Here we assume that all sequences in the group share # the same prompt. This may not be true for preempted sequences. # (这里我们假设一个seq_group下的所有序列的prompt都是相同的) # =========================================================================== # 取出这个seq_group下处于waiting状态的序列 # =========================================================================== seq = seq_group.get_seqs(status=SequenceStatus.WAITING)[0] # =========================================================================== # 取出这个seq所有的逻辑块 # =========================================================================== num_required_blocks = len(seq.logical_token_blocks)
# =========================================================================== # block上的滑动窗口(可暂时假设其值为None,先忽略不看 # =========================================================================== if self.block_sliding_window is not None: num_required_blocks = min(num_required_blocks, self.block_sliding_window) # =========================================================================== # 计算当前所有可用的物理块数量,List[PhysicalTokenBlock] # =========================================================================== num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
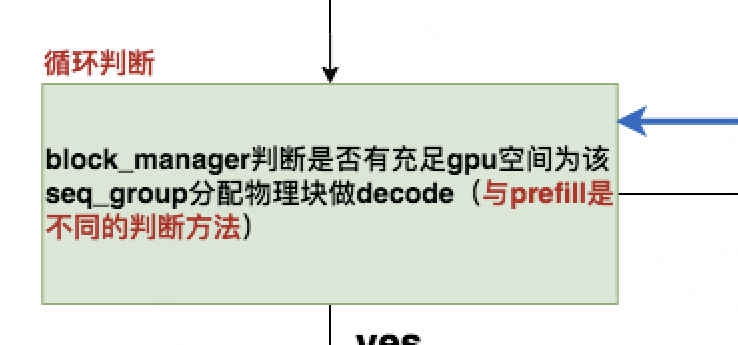
# vllm/core/block_manager_v1.py def can_append_slot(self, seq_group: SequenceGroup) -> bool: """ 对于这个seq_group,我们检查对于其中的每一个seq, 是否能至少分配一个空闲物理块给它 """ # Simple heuristic: If there is at least one free block # for each sequence, we can append. num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks() num_seqs = seq_group.num_seqs(status=SequenceStatus.RUNNING) return num_seqs <= num_free_gpu_blocks
# ============================================================================== # Fix the current time. # 获取当下时间 # ============================================================================== now = time.time()
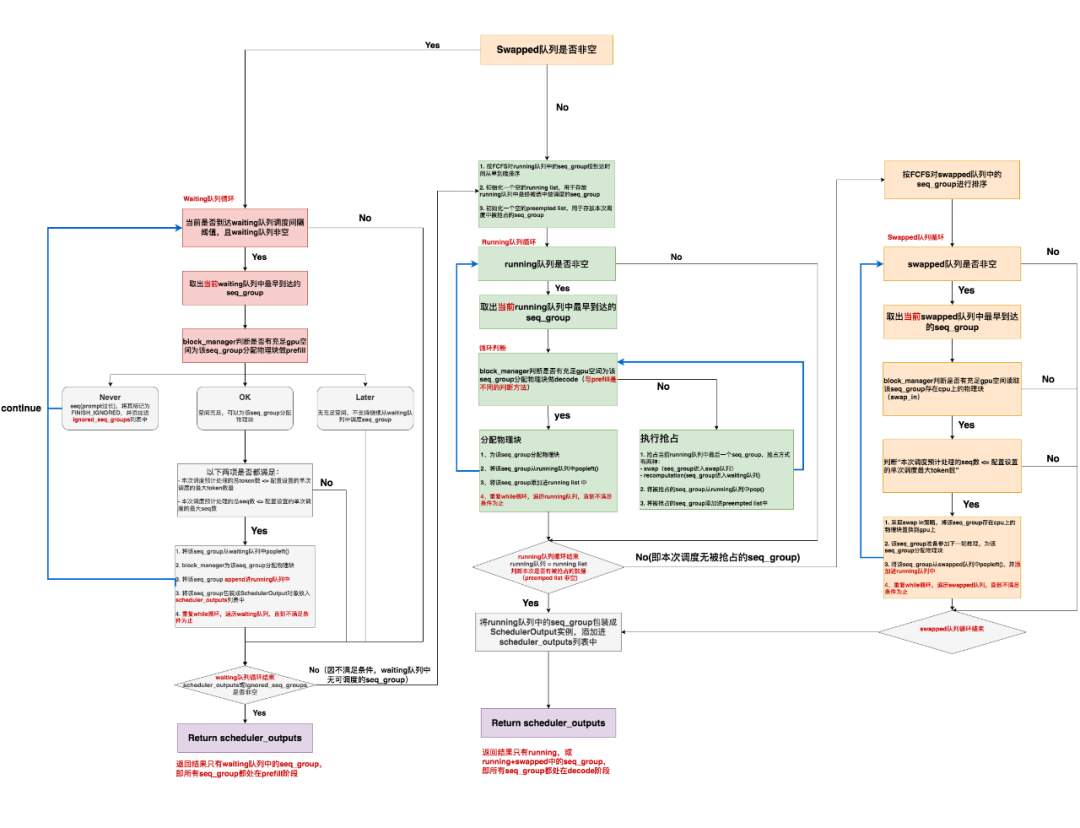
# ============================================================================== # Join waiting sequences if possible. # 如果swapped队列为空 # ============================================================================== if not self.swapped: # ========================================================================== # ignored_seq_groups:记录因太长(所需的blocks和总blocks之间的差值超过阈值了), # 而无法继续做生成的seq_group,这些seq_group中的seq状态都会被标记为 # FINISHED_IGNORED,表示直接不处理他们 # ========================================================================== ignored_seq_groups: List[SequenceGroup] = [] # ========================================================================== # 记录本次被调度的seq_group # ========================================================================== scheduled: List[SequenceGroup] = [] # ========================================================================== # The total number of sequences on the fly, including the # requests in the generation phase. # 计算Scheduler running队列中还没有执行完的seq数量 # ========================================================================== num_curr_seqs = sum(seq_group.get_max_num_running_seqs() for seq_group in self.running) curr_loras = set( seq_group.lora_int_id for seq_group in self.running) if self.lora_enabled else None
# ========================================================================== # Optimization: We do not sort the waiting queue since the preempted # sequence groups are added to the front and the new sequence groups # are added to the back. # lora相关的,可以暂时不看 # ========================================================================== leftover_waiting_sequences = deque() # ========================================================================== # 本次调度处理的token总数 # ========================================================================== num_batched_tokens = 0
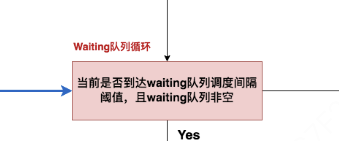
# ========================================================================== # 开启新一次调度(while循环不结束意味着本次调度不结束, # 跳出while循环时意味着本次调度结束了) # 开启新一次调度的条件:当waiting队列中有等待处理的请求,且当前时刻可以处理请求 # ========================================================================== while self._passed_delay(now) and self.waiting: # ===================================================================== # 取出waiting队列中的第一个请求,也即最早到达的请求(seq_group) # ===================================================================== seq_group = self.waiting[0] # ===================================================================== # 统计该seq_group中s处于waiting的seq的数量 # ===================================================================== waiting_seqs = seq_group.get_seqs( status=SequenceStatus.WAITING) # ===================================================================== # 从waiting队列中取出来的seq_group,其seq数量一定是1 # ===================================================================== assert len(waiting_seqs) == 1, ( "Waiting sequence group should have only one prompt " "sequence.") # ===================================================================== # 获取该seq的序列长度(如果该seq_group来自之前被抢占的请求, # 那么这个长度不仅包括prompt, # 还包括output) # ===================================================================== num_prefill_tokens = waiting_seqs[0].get_len() # ===================================================================== # 如果从waiting队列中取出的这条seq的长度 > 每次调度能处理的最大序列长度, # 那么就打印警告信息,同时把这条seq的状态置为FINISHED_IGNORED, # 并将对应seq_group装入ignored_seq_groups中, # 然后将其从waiting列表中移除,不再处理 # ===================================================================== if num_prefill_tokens > self.prompt_limit: logger.warning( f"Input prompt ({num_prefill_tokens} tokens) is too " f"long and exceeds limit of {self.prompt_limit}") for seq in waiting_seqs: seq.status = SequenceStatus.FINISHED_IGNORED ignored_seq_groups.append(seq_group) self.waiting.popleft() continue # ===================================================================== # If the sequence group cannot be allocated, stop. # 决定是否能给当前seq_group分配物理块 # can_allocate返回值可能有三种: # AllocStatus.NEVER:不分配; # AllocStatus.OK:可以分配; # AllocStatus.LATER:延迟分配 # ===================================================================== can_allocate = self.block_manager.can_allocate(seq_group) # 若是延迟分配,则说明现在没有足够的block空间,所以跳出while循环(不继续对waiting队列中的数据做处理了) if can_allocate == AllocStatus.LATER: break # 如果不分配,说明seq长得超出了vLLM的处理范围,则后续也不再处理它,直接将该seq状态标记为FINISHED_IGNORED elif can_allocate == AllocStatus.NEVER: logger.warning( f"Input prompt ({num_prefill_tokens} tokens) is too " f"long and exceeds the capacity of block_manager") for seq in waiting_seqs: seq.status = SequenceStatus.FINISHED_IGNORED ignored_seq_groups.append(seq_group) # 记录因为太长而无法处理的seq_group self.waiting.popleft() # 将该seq_group从waiting队列中移除 continue
# ===================================================================== # lora推理相关的部分,可暂时忽略 # ===================================================================== lora_int_id = 0 if self.lora_enabled: lora_int_id = seq_group.lora_int_id if (lora_int_id > 0 and lora_int_id not in curr_loras and len(curr_loras) >= self.lora_config.max_loras): # We don't have a space for another LoRA, so # we ignore this request for now. leftover_waiting_sequences.appendleft(seq_group) self.waiting.popleft() continue
# ===================================================================== # If the number of batched tokens exceeds the limit, stop. # max_num_batched_tokens:单次调度中最多处理的token数量 # num_batched_tokens:本次调度中累计处理的token数量 # 如果后者 > 前者,则结束本次调度 # ===================================================================== num_batched_tokens += num_prefill_tokens if (num_batched_tokens > self.scheduler_config.max_num_batched_tokens): break
# ===================================================================== # The total number of sequences in the RUNNING state should not # exceed the maximum number of sequences. # num_new_seqs: 当前seq_group中状态为“未执行完”的序列的数量 # num_curr_seqs:当前调度轮次中,状态为"未执行完“的序列总数 # 如果超过了我们对单次调度能执行的序列总数的阈值,就结束本次调度 # ===================================================================== num_new_seqs = seq_group.get_max_num_running_seqs() if (num_curr_seqs + num_new_seqs > self.scheduler_config.max_num_seqs): # 单次迭代中最多处理多少个序列 break
# ============================================================================== # NOTE(woosuk): Preemption happens only when there is no available slot # to keep all the sequence groups in the RUNNING state. # In this case, the policy is responsible for deciding which sequence # groups to preempt. # 如果swap队列非空,且本次没有新的需要被发起推理的seq_group, # 则对running队列中的seq_group, # 按照 "当前时间-该seq_group到达时间" ,从早到晚排列running队列中的seq_group # ============================================================================== self.running = self.policy.sort_by_priority(now, self.running)
# ============================================================================== # Swap in the sequence groups in the SWAPPED state if possible. # 对于swapped队列中的seq_group,按照到达时间从早到晚排序 # ============================================================================== self.swapped = self.policy.sort_by_priority(now, self.swapped) # ============================================================================== # 如果本次调度没有新安排的被抢占的seq_group(即preempted为空) # ============================================================================== if not preempted: # ============================================================== # 计算running队列中,所有seq_group下,“到生命周期结束为止最多运行的seq数量”的总和 # ============================================================== num_curr_seqs = sum(seq_group.get_max_num_running_seqs() for seq_group in self.running) # ============================================================== # lora部分,暂时忽略 # ============================================================== curr_loras = set( seq_group.lora_int_id for seq_group in self.running) if self.lora_enabled else None
# ============================================================== # 当swapped队列非空时 # ============================================================== while self.swapped: # ============================================================== # 取出swap队列中最早被抢占的seq_group # ============================================================== seq_group = self.swapped[0] # ============================================================== # lora相关,暂时不看 # ============================================================== lora_int_id = 0 if self.lora_enabled: lora_int_id = seq_group.lora_int_id if (lora_int_id > 0 and lora_int_id not in curr_loras and len(curr_loras) >= self.lora_config.max_loras): # We don't have a space for another LoRA, so # we ignore this request for now. leftover_swapped.appendleft(seq_group) self.swapped.popleft() continue
# ============================================================== # If the sequence group cannot be swapped in, stop. # 判断一个被swap的seq_group现在是否能重新running起来 # 【判断条件】: # 当前gpu上可用的物理块数量 - 重新跑起这个seq_group需要的物理块数量 # >= 水位线物理块数量 # 其中: # 后者 = 在被swap之前它已经使用的物理块数量(去重过了) # + 若能再次跑起来它至少需要的物理块数量 #(假设每个seq至少需要1个物理块) # ============================================================== # 如果不能,则意味着当前没有充足资源处理swap队列中的seq_group,则直接跳出循环 if not self.block_manager.can_swap_in(seq_group): break
# ============================================================== # The total number of sequences in the RUNNING state should not # exceed the maximum number of sequences. # 如果对于swap队列中的这个seq_group,当前gpu上有充足资源可以让它重新跑起来的话: # ============================================================== # 取出这个seq_group在剩余生命周期内将并行运行的最大序列数 num_new_seqs = seq_group.get_max_num_running_seqs() # 如果已超过一次调度中能处理的最大序列数,则不再对该seq_group进行处理 if (num_curr_seqs + num_new_seqs > self.scheduler_config.max_num_seqs): break # lora部分暂时不看 if lora_int_id > 0: curr_loras.add(lora_int_id) # ============================================================== # 走到这一步,说明可以对swapped队列中的这个seq_group做相关处理了, # 先把它从队列中移出去 # ============================================================== self.swapped.popleft() # ============================================================== # 将该seq_group下所有cpu块置换回gpu块, # 并将其下每个seq的状态从swapped改成running # ============================================================== self._swap_in(seq_group, blocks_to_swap_in) # ============================================================== # 假设其正常做推理了,假设现在生成了一个token,要如何分配物理块(参见上面注释) # ============================================================== self._append_slot(seq_group, blocks_to_copy) num_curr_seqs += num_new_seqs self.running.append(seq_group)
self.swapped.extendleft(leftover_swapped)
# ============================================================================== # 如果本次调度有新安排的被抢占的seq_group(即preempted不为空),那就准备将最终的running队列 # 作为scheduleroutputs返回 # ============================================================================== # Each sequence in the generation phase only takes one token slot. # Therefore, the number of batched tokens is equal to the number of # sequences in the RUNNING state. # 由于每个seq一次只生成1个token,因此num_batched_tokens = 状态为running的seq数量 num_batched_tokens = sum( seq_group.num_seqs(status=SequenceStatus.RUNNING) for seq_group in self.running)