从一句情话来了解语言模型的发展
问题定义
一段文字,例如:今夜月色真美。代表的是什么含义?如果在春天温度适宜的 9、10 点站在阳台的人对你脱口而出地说出这句话,你会怎么理解这句话,亦或者你会怎么回应他(她)呢?
这句话是十九世纪末的文学家 夏目漱石对 I love you 的英译日标注结果(今夜は月が綺麗ですね)。根据他的标注 我爱你 和 今夜月色真美 表达了相同的意义。但是计算机这么认为吗?输入 今夜月色真美,它理解这句话和 我爱你 是相似的含义吗?这个可以被归类为自然语言理解(NLU)领域的语义匹配问题。
众所周知在计算机中一切都是数字信号,那么如果想让计算机理解一句话的含义,解决 今夜月色真美 和 我爱你 的语义匹配问题,那么先决问题是将一句话表示为一系列的数字信号。一个理所当然的想法是将语料库中的每一个词w用一个唯一的 n 维向量v=[v1,v2,…,vn]来表达,那么数个向量的序列seq={v1,v2,…,vm}就可以表达一句话,这一类方法就是词嵌入模型。本期文章通过对比这个 case 在 one-hot 、n-gram 、word2vec 、BERT 四种语言模型的结果,分析各个方法的优缺点。
one-hot
一个最简单的想法就是使用 one-hot 向量来表达一个词。具体流程:
- 遍历语料库,统计词的集合W,集合大小为K
- 将每个词在集合W中的下标的元素为 1,其他位置元素为 0,构建长度为K的 0-1 向量
假设我们对 今夜月色真美 的分词结果为:今夜、月色、真、美。那么使用 one-hot 向量就能将这个句子表示为4×K的 0-1 矩阵。我们假设语料库中一共有 10 个词:{我、爱、你、今夜、月色、真、美、今晚、漂亮、喜欢}。那么V今夜=[0,0,0,1,0,0,0,0,0],V今晚=[0,0,0,0,0,0,0,1,0,0],V我=[1,0,0,0,0,0,0,0,0,0]。
one-hot 词嵌入方法优点在于简单,并且最大程度地保留了每个词的信息。但是缺点也很明显:
- 对于从未出现在语料库中的未登录词,无法进行兼容。假如词
恨需要编码,那么只能编码为零向量,否则需要对所有词向量进行更新,扩展向量维度。 - 丢失了词与词之间的相关信息。例如
今夜和今晚本身是相近语义的词,但是通过 one-hot 编码的向量差异并没有比我和今夜小。
统计语言模型:N-GRAM
one-hot 词嵌入方法有以上的缺点,我们希望去改进这些缺点。所以我们先关注于第二点,如何保留词与词之间的相关关系。很自然的,会想到用一个词以及其邻近的词来共同表示这个词。例如:今夜 和 今晚 由于他们是相似词,所以他们是互相可以替换。例如将 今晚天气真好 替换为 今夜天气真好。这句话的语义不会发生大的变化。因此一个假设:对于词 A 与词 B,A,B∈W,W是语料库中所有词的集合有:
if R(A,B)=1 then P(C∣A)=P(C∣B),C∈W
P(C∣A)表示在一条语料中出现词A后出现词C的概率。以上一个例子为例,对于天气这个词来与今晚和今夜分别共现的语料条数为N和M。假设出现今晚的语料共N′条,今夜的语料共M′条,那么按照假设会有N′N=M′M。
假设我们已经统计出了 今晚 这个词对其他所有词(包括今晚)的条件概率P(C∣今晚)。那么我们可以把 one-hot 向量上的每一个分量替换为今晚对这个位置上对应词的条件概率。这样构成的向量在上述假设下,今晚和今夜的结果应是相似的。并且在这个词向量上所有分量之和等于 1。
基于共现条件概率构建的词向量在短文本上效果还不错,但是仍然有两个的缺点:
- 违反了人书写的概率模型,因为人书写都是自然的从左到右。一个词对出现在其前面的词不会产生影响。
- 无视了距离对词的依赖关系的影响,假设词同等依赖于所有位置的词。但是对于长文本而言,这个假设显然不成立。
为了补充以上两个缺点,我们考虑 N-Gram 统计概率模型代替共现条件概率。
N-Gram 模型假设人的书写过程是随机过程,其概率图为一个有向无环图:

按照上图,今夜月色真美 这个语料中每个词出现的概率为P(w4=美∣w0=start,w1=今夜,w2=月色,w3=真),P(w3=真∣w0=start,w1=今夜,w2=月色),P(w2=月色∣w0=start,w1=今夜),P(w1=今夜∣w0=start)。
进一步为了降低距离对词依赖的影响,也同时为了语料库规模与计算能力的局限所考虑,N-Gram 模型假设人书写的随机过程满足N阶马尔科夫条件。如果满足二阶马尔科夫条件的模型称为 Bi-Gram。
在 Bi-Gram 下每个词出现的概率可以描述为P(w4=美∣w3=真),P(w3=真∣w2=月色),P(w2=月色∣w1=今夜),P(w1=今夜∣w0=start)。
由此共现条件概率的两个缺点使用 N-Gram 模型能很好的弥补。在实际使用上一般会将start单独作为作为一个词,会将 今夜月色真美 改写为 [start]今夜月色真美,然后在语料中统计P(w1=今夜∣w0=start)。同理我们可以在向量中加入 Uni-Gram(满足一阶马尔科夫条件)、Tri-Gram(满足三阶马尔科夫条件),甚至可以加入更高阶的 Gram 模型,来组成 N-Gram 的词嵌入,在实际应用中一般不会使用高于三阶的模型。
N-Gram 词嵌入在实际应用上游很多的 Trick。这些 Trick 主要要解决有限语料库与概率估计之间的权衡。对于长尾的词组,直接使用统计值进行估计往往不准确,可能会存在偏差。更多的时候会采用统计平滑方法对统计条件概率进行平滑,常用 Good-Turing 平滑或者 Kneser-Ney 平滑等,在这篇博客中有对其详细介绍:NLP 笔记 - 平滑方法(Smoothing)小结 笔记 - 平滑方法(Smoothing)小结/)。
基于 N-Gram 词嵌入在实践过程中还有很多基于矩阵分解的变体,因为所有词向量的矩阵可以构成一个高维对称矩阵,在这个矩阵上可以应用类似于 SVD 分解、QR 分解等等方法对矩阵进行分解,得到性质更好的向量。
神经语言模型
N-Gram 是统计语言模型的一个经典方法。当满足其假设条件的情况下,统计语言模型的效果很好。但是在实际应用场景情况下,很难满足统计语言模型的假设条件:
- 书写过程是一个先决定一个词,再决定下一个词的序列随机过程
- 随机过程满足N阶马尔科夫条件
但是在实际的场景下上述两个假设条件往往难以满足。最简单的例子是,我们在高考作文中经常会写三段式议论文文章,往往会先在开头引出结论,然后再在后续对开头的结论进行证明,最后在文章末尾对文章的论点进行总结。从这种书写方式来说,首先开头外的所有文字都是为开头的论点服务,因此马尔科夫条件的 N 阶可能会非常高,甚至说无法满足这个条件。其次词的随机过程首先会有一个名为论点的先验分布。其次 今天天气不错哇 和 天气不错哇,今天,在口头表达中表达的是相同意思,但是其词序有差异。这说明人的书写顺序并非是从左到右的阅读顺序。在不满足其假设条件的情况下。N-Gram 语言的效果往往会大打折扣。因此在神经语言模型兴起之后,基于 Mask Language Model(MLM)的嵌入方法开始流行。
MLM 的基本思想是将一段文字随机隐藏一部分文字,学习目标是重构这段文字。一般我们把一个单位的文字称为一个 token 例如 今夜月色真美 这段文字,Mask 真 这个词之后,这段文字变成了 今夜月色[mask]美。模型的任务就是预测被 mask 的 token 是什么。常用的 Mask 策略有:
- 随机 Mask 一个 token(CBOW)
- 只保留一个 Token,其他所有 Token 都被 Mask(SKIP-GRAM)
- 随机 Mask 一定比例的 Token(BERT)
- 随机 Mask 一段 Token 序列(SpanBERT)
- 按照语序从后往前 Mask 一段 Token 序列(XLNET)
由于篇幅限制,本文只介绍 Word2Vec 和 BERT 以及 XLNET。
Word2vec
上文所说的 CBOW 和 SKIP-GRAM 都是 word2vec 的两种训练方法。相信大家对 word2vec 的大名都有一定了解。作为词嵌入方法上最具代表性的模型,目前在工业界基本上是嵌入方法的代表模型。并且在之外有 GloV、 ELM 等一系列衍生方法。各位感兴趣的读者可以了解一下。
word2vec 的模型架构整体上比较简单:
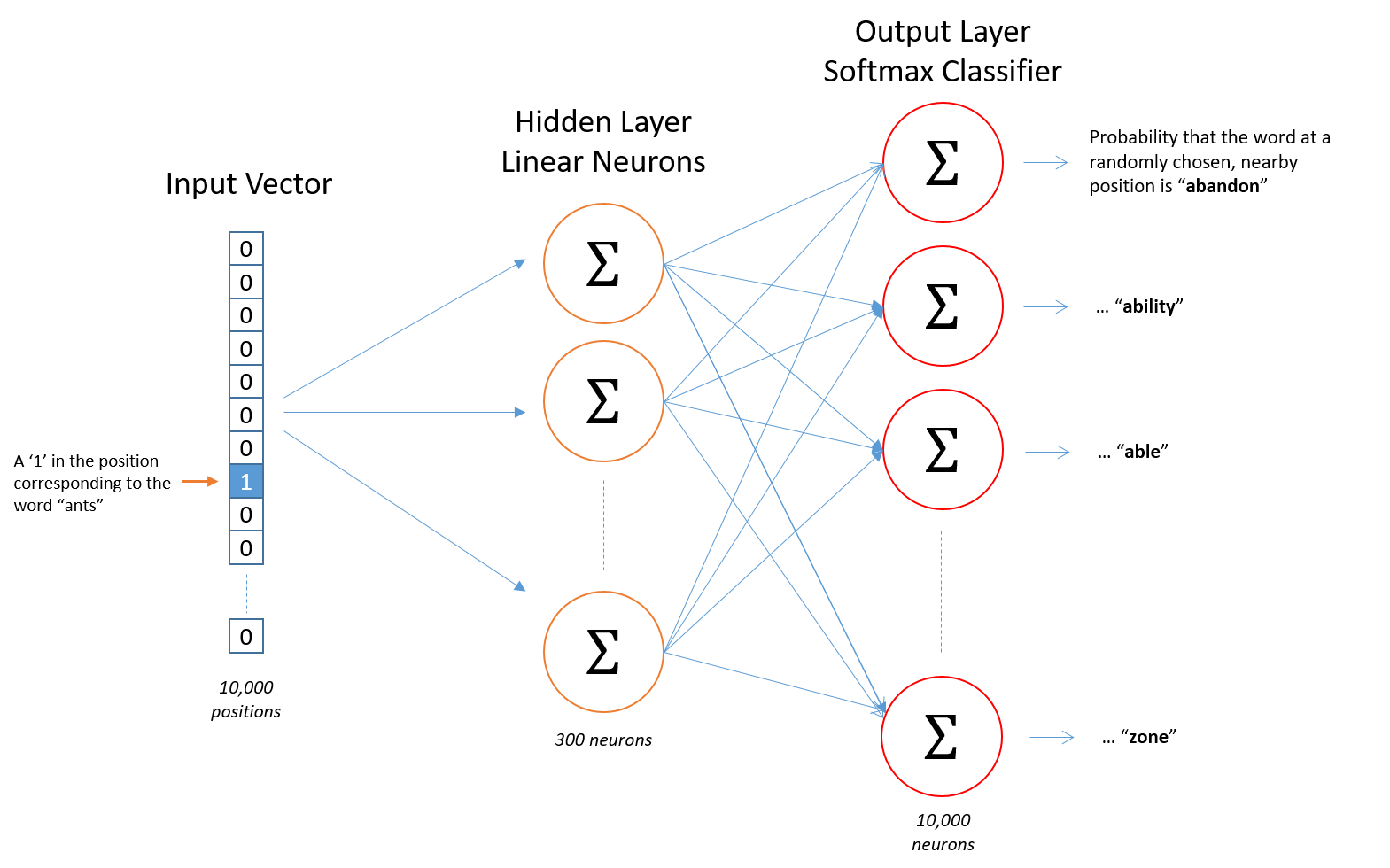
- Input Vector:CBOW 模型的输入层是被 mask 的 token 附近多个被保留 token 的 one-hot 向量之和,SKIP-GRAM 模型的输入层是被保留的一个 token 的 one-hot 向量
- Hidden Layer:两到三层的 MLP
- Output Layer:使用 softmax 激活函数来对 token 进行预测,CBOW 模型预测被 mask 的 token,SKIP-GRAM 预测被保留的 token 附近多个被 mask 的 token。见图:
- 将隐藏层的第一层的矩阵A提取出来,将每个词的 one-hot 向量x与A的乘积Ax作为这个词的向量(实际上就是取了A矩阵对应位置的行向量)。
使用 Word2Vec 要如何对 今夜月色真美 及进行理解呢?为了方便描述我们不妨假设除了 美 之外的词,现在模型已经完全理解了。现在的问题是如何使用现有的语料对 美 进行学习。由于每次使用反向传播来更新矩阵A的值,而且将 word2vec 将未被 mask 的 token 作为输入,所以每次训练的是未被 mask 部分的 token 的向量。因此直接的想法是将 美 保留,今夜月色真 被 mask。这样每次训练的就是 美 这个词,通过语料库中所有带 美 这个 token 的语料,我们可以不断更新矩阵A的值,得到 美 的向量。
上述描述的就是 SKIP-GRAM 模型。通过在语料库中不断学习,模型学习到 美 描述了 今夜月色真。通过大量的语料,模型也会学习到 美 用来描述其他东西,得到在全体语料库的 美 表达的共同点(向量)。
与 SKIP-GRAM 相反,如果要学习 美 的向量,需要将 美 保留,而 mask 其他 token。如果要训练 美 的想来那个,那么 今夜真美 预测 月色,今夜月色美 预测 真 这些样本需要参与模型训练。从学习方式上看,CBOW 一次会对多个 token 进行学习,在学习一个具体的 token 的时候会受到同句其他 token 的影响。因此在一些长尾 token 上 CBOW 效果不如 SKIP-GRAM。
通过 Word2vec 我们可以学习到 今夜、月色、真、美、我、爱、你。每个 token 的表达。那么可以得到 今夜+月色+真+美=我+爱+你 吗?不考虑特殊的语料库的情况下,Word2vec 很难学习到这个信息。因为从上文描述的学习方法来看,word2vec 学习的是在统计情况下,一个普遍的上下文情况下一个词的意义。但是对于一个特定的对话场景下一个词在不同的语境下的信息无法表达。最明显的就是 苹果手机 和 山东烟台苹果 两句话的中 苹果 是表达的不是同一个意思。而对于 Word2vec 这类词嵌入模型,一个 token 的表达是固定的。
回到 今夜月色真美,其中说的就是今夜的月色吗?为了方便解释,我们不妨将 今夜月色 解释为是一种指代,指代的是 你。所以这句话可以被转换为 你真美,另外 今夜月色 在这句话中又承担了环境的语境。完全展开为 今天晚上在月色的衬托下你真美,进一步在这种氛围下赞美异性,所表达的含义即是 I love you。但是 word2vec 这种静态的词嵌入方法下,一个词只会有一种语义,那么在包含两种语义的 今夜月色 成为了这段翻译的主要问题。
BERT:Bidirectional Transformer
那么如何才能保留一个词在不同语境下的信息呢?很简单,直接学习一整句话就可以了。之前我们在训练 word2vec 的时候,采用了第一层的隐层权重作为每个词的权重。但是实际上我可以把任意一个 token 序列放入这个模型中,然后取任意隐藏层的输出结果作为句子级的表示。这类预训练模型主要有两种类型:
- frozen 模型:在预训练语料上训练后,模型参数固定不变。
- fine-tuning 模型:在预训练语料上训练后,会随着子任务继续微调模型参数。
frozen 模型的代表是 ELMo,是 NAACL18 Best Paper。fine-tuning 模型的代表是 Google 在 2018 年发表的 BERT 模型。关于 BERT,强烈推荐大家看财大气粗的 Google 在 19 年发表的论文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,在模型中 Google 对于各种 BERT 上的 trick 进行了实验效果对比。包括 Mask 策略的选择,模型参数的选择等等。本文就不详细展开了。
BERT 是 Bidirectional Transformer 的缩写,关于 Transformer 大家可以看之前写的这篇博客:算法工程师必知必会的经典模型系列一:Transformer 模型串讲。Bidirectional Transformer 相较于 Attention Is All You Need 中描述的 Transformer 差异主要体现在只使用了其中的 Encoder 部分,但是不代表选择 Encoder 部分就是最优的。甚至在 Google 后续的论文中指出使用完整的 Encoder+Decoder 部分的 Transformer 效果更好。
BERT 模型通过将前一层各个位置的输出序列作为下一层 Transformer 的输入,这样不断堆叠 Transformer。然后得到隐藏层的输出序列。如下图所示,BERT 模型的输入是序列:{E1,E2,…En},通过两层 Bidirectional Transformer。得到输出序列:{T1,T2,…,Tn}。
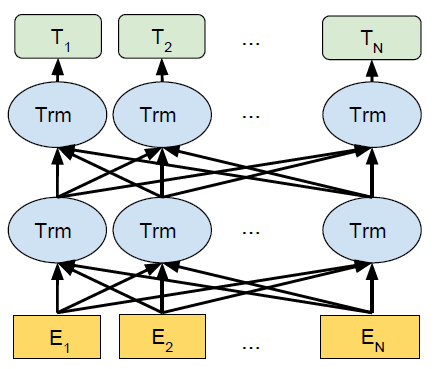
模型本身很简单,但是这篇文章贡献了两个对 NLP 领域影响巨大的重要结论:
- 证明了 MLM 在无监督预训练模型能够为 fine-tuning 阶段的监督模型提供信息
- 证明了 pre-train+fine-tuning 的两阶段模型对特定任务迁移学习的效果
BERT 没有像 Transformer 论文中直接用三角函数值计算 Position Embedding。而是采用嵌入学习的方法,对 Position Embedding、Segment Embedding 和 Token Embedding 进行训练,在模型输入的时候如下图所示将 Position Embedding、Segment Embedding 和 Token Embedding 相加作为模型的输入。
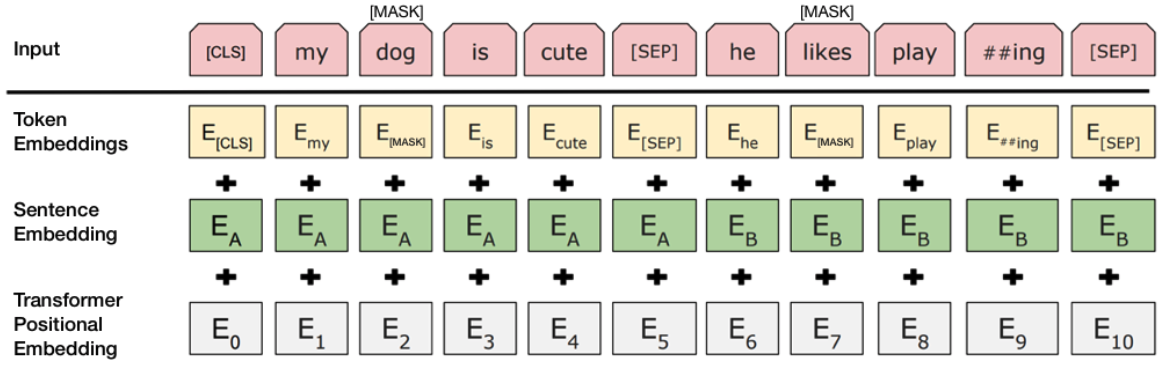
在预训练过程中,BERT 将句子中的 15% 的 Token 隐藏。然后将还原这个句子作为学习任务。因为隐藏一个 token 相当于在这个 token 上加了一段噪声,使这个 token 的信息丢失,预测还原句子相当于将这段噪声去除,还原这个 token 的信息。因此这类模型也被称为 Denoising AutoEncoder(DAE)模型。
在原始论文中,被 Mask 的 Token 是固定的。比如 今夜月色真美 这个句子,如果被 mask 后序列为 今夜[mask]真[mask],那么在每个 epoch 的训练中都是这个序列。但是后续试验证明,采用 Dynamic Mask,即每次训练时实时对样本序列进行 Mask 效果优于固定 Mask 方法。
在原始论文中,除了 MLM 外,还会将预测下一句(Next Segment Predict,简称 NSP)作为一个学习任务,与 MLM 共同预训练 BERT 模型。但是在后续试验证明去除 NSP 在多个任务上效果会更好,并且训练速度更快。并且有类似于 XLNET、StructBERT 等模型指出一个合适的预训练任务,能够提升 BERT 的效果。
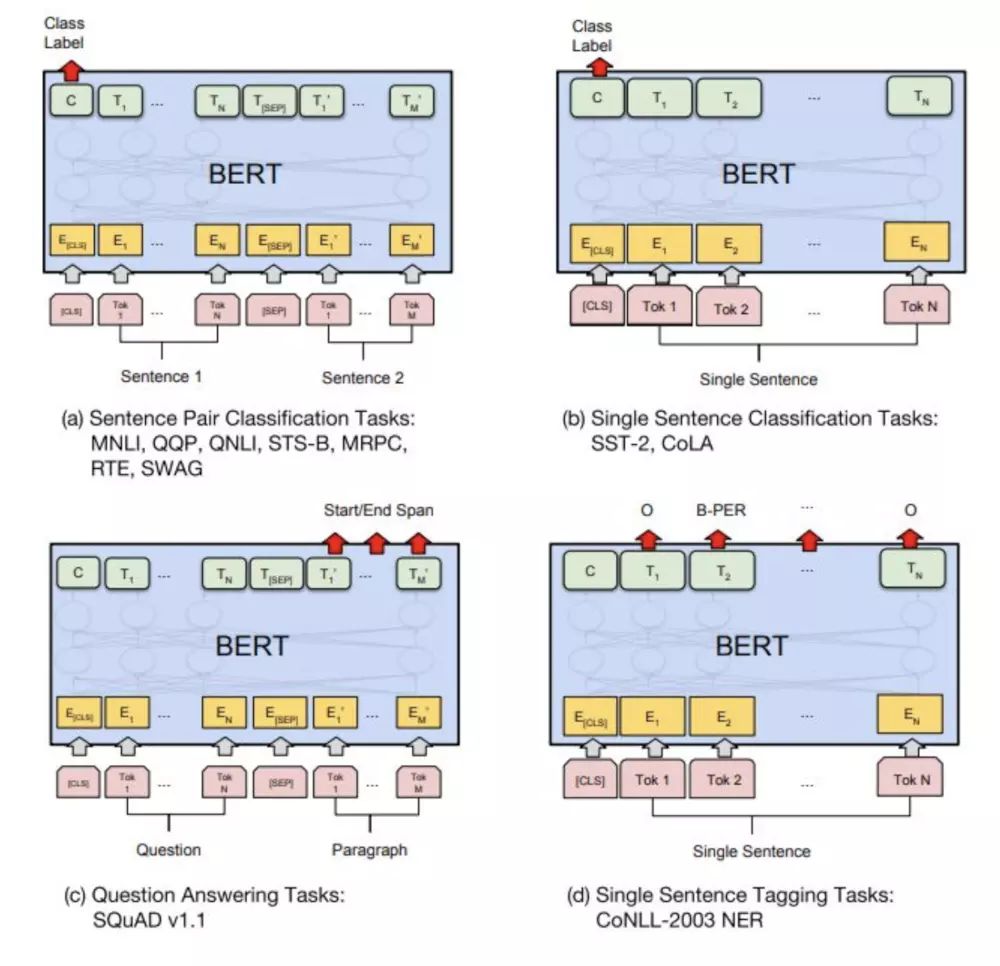
BERT 官方在 GLUE 数据集上对不同的任务进行 fine-tuning 时采用了如下图的方式对不同类型的学习任务进行 fine-tuning:
- 对于单句分类任务,将[CLS]的输出作为句子的表达,后续通过连接一层 MLP+tanh 激活函数 +layer normalization 后连接分类网络。
- 对于句对分类任务,将其中一句作为第一句,另一句作为第二句。然后按照单句分类进行预测。
- 对于对话任务,使用末尾的一段 token 对应的输出进行预测。
- 对于序列标注任务,使用每个 token 的输出进行预测。
我们回到 Word2Vec 对翻译 今夜月色真美 的问题,无法通过语境,来将 今夜月色 识别为 你。对于 BERT,来说这个问题就不是问题。对于 真美 这段文字来说,今夜月色 是一个代词。对于这个句子整体来说 今夜月色 是烘托气氛的环境。那么对于 真美 来说,今夜月色 不会影响到 真美 这段文字的含义,但是对于 今夜月色 来说,由于 真美 的存在所有导致了 今夜月色 成为了指代。针对这种情况,BERT 通过 Attention 机制有效评估了一个句子中的各个 token 对一个 token 的影响。
- 本文地址:从一句情话来了解语言模型的发展
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出