Flink:什么是 Watermark?
1、什么是 watermark
watermark 网上有翻译成水印,但更应该是水位线,即 Flink 接受的数据就相当于浮在水面的物体, 基于物理知识,水位线的高度只会升高不会降低,那么每当新数据进来,会重新计算水位线的时间,计算结果小于当前水位线时间,则不会更新现有的水位线。 当水位线到达窗口触发时间时才会触发窗口的计算。watermark 的意义在于数据无序传递的时候有一定容错率,如果晚来的数据在容错范围之内,会当做正常传递来处理。
乍一看还是懵逼,那么就看下面的分析。
2、什么是流处理
Flink 被称为真正的流式实时计算框架,其批处理中是流处理的特殊情况。而所谓的流处理,本质特点是在处理数据时,接受一条处理一条。而批处理则是累积数据到一定程度在处理。这是他们本质的区别。
假如我们自己写一个流式框架。我们该如何处理消息。如下,我们看到消息按照顺序一个个发送,接受后按照顺序处理,这是没有什么问题的。

如果消息不按照顺序发送,产生了乱序,这时候该怎么处理?

其实水位线 Watermark 就是其中的解决方案之一。
3、水位线怎么解决乱序
要理解:水位线和 Flink 窗口(window )机制是一起用的,不可分割来看。先看前置基础——Flink 窗口,时间机制
3.1、Flink 窗口机制简单概括
对于 Flink,如果来一条消息计算一条。。。这样搞,计算非常频繁而且消耗资源,如果想做一些统计这是不可能的。所以对于 Spark 和 Flink 都产生了窗口计算的概念。
下面详细分析,简单粗暴的说:如果我们想看到过去一分钟,过去半小时。。。访问数据,这时候我们就需要窗口。即:翻滚窗口(Tumbling Window,无重叠),滚动窗口(Sliding Window,有重叠),和会话窗口(Session Window,活动间隙)。
滚动窗口
将每个元素分配给固定窗口大小的窗口。滚动窗口大小固定且不重叠。例如,指定大小为 5 分钟的滚动窗口,则将执行当前窗口,并且每五分钟将启动一个新窗口,如下图所示: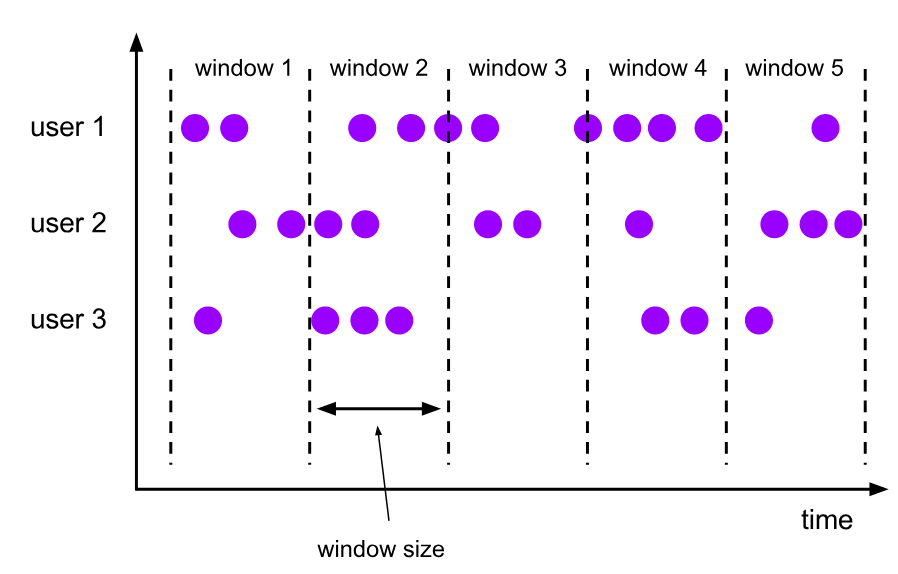
滑动窗口
将每个元素分配给固定窗口大小的窗口。类似于滚动窗口分配器,窗口的大小由窗口大小参数配置。另外一个滑动参数控制滑动窗口的启动频率 (how frequently a sliding window is started)。因此如果滑动参数的大小,小于窗口大小,滑动窗口就可以重叠。在这种情况下,元素被分配到多个窗口。
例如,可以使用窗口大小为 10 分钟的窗口,滑动参数为 5 分钟。这样,每 5 分钟会生成一个滑动窗口,包含最后 10 分钟内到达的事件,如下图所示。
会话窗口
通过活动会话分组元素。与滑动窗口相比,会话窗口不会重叠,也没有固定的开始和结束时间。相反,当会话窗口在一段时间内没有接收到元素时会关闭。
例如,不活动的间隙,会话窗口分配器配置会话间隙,定义所需的不活动时间长度(defines how long is the required period of inactivity)。当此时间段到期时,当前会话关闭,后续元素被分配到新的会话窗口。
窗口自定义
这是 flink 灵活的地方,基本操作:
window:创建自定义窗口
trigger:自定义触发器
evictor:自定义 evictor
apply:自定义 window function
3.2、Flink 时间机制简单概述
一个事件发生了,肯定是有时间概念的,这个时间,在 Flink 中被称之为事件时间,也就是 Event Time,也就是事件时间,除此之外,还有处理时间 Processing Time,和提取时间 Ingestion Time 。这三个时间区别和联系看下图,分别列出了事件时间、处理时间、提取时间的先后顺序。
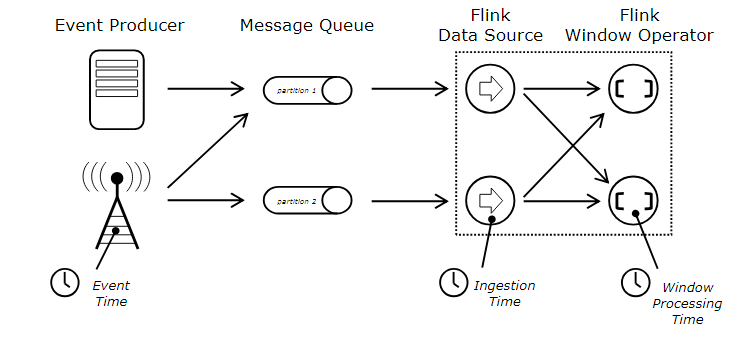
Event Time
大白话就是这个事儿发生的真实时间(源头)。举个例子,产生日志,其中日志的时间戳就是发生时间,即事件时间。
严谨的说,事件时间是每个事件在其设备上发生的时间。在进入 Flink 之前就已经存在,此时间通常在进入 Flink 之前嵌入记录中,并且可以从每个记录中提取该事件时间。事件时间程序必须指定如何生成事件时间水位线,这是表示事件时间进度的机制,下一小节细说水位线,先知道有这个概念。
在一个理想的情况下,无论事件何时到达或如何排序,事件时间的处理将产生完全一致的和确定的结果。但是,除非事件严格的按时间戳顺序到达 Flink,否则事件时间处理会在等待无序事件时产生一些延迟。由于只能等待一段有限的时间,因此限制了确定性事件时间应用程序的可能性。
假设所有数据都已到达,事件时间操作将按预期运行,即使在处理无序或延迟事件或重新处理历史数据时也会产生正确且一致的结果。例如,每小时事件时间窗口将包含带有落入该小时的事件时间戳的所有记录,无论它们到达的顺序如何,或者何时处理它们。
注意,有时当事件时间程序实时处理实时数据时,它们将使用一些处理时间操作,以确保它们及时进行。
Ingestion Time
大白话就是事件进入 Flink 的时间,即提取时间。每个记录在 source 操作里获取当前系统的时间作为提取时间,后续操作统一使用该时间。
严格的说:提取时间在概念上位于事件时间和处理时间之间。
- 与处理时间相比,它早一些,但可以提供更可预测的结果。因为提取时间使用稳定的时间戳(在源 source 处分配一次,后续操作一直用),所以对记录的不同窗口操作将引用相同的时间戳,而在处理时间中,每个窗口 operate 可以将记录分配给不同的窗口(基于本地系统时钟和任何运输延误)。
- 与事件时间相比,提取时间程序无法处理任何无序事件或后期数据,但程序不必指定如何生成水位线。在内部,提取时间与事件时间非常相似,但具有自动时间戳分配和自动水印生成功能。
Processing Time
大白话就是做这个事情的时间,即处理时间。它也是执行操作的机器的当前系统时间(每个算子都不一样),图里这个事件已经进入了 Flink。
严谨的说:当流程序在处理时间运行时,所有基于时间的操作(如时间窗口)将使用相应 operator(算子,以下都简称为 operator)所在的机器的系统时钟。每小时处理时间窗口将包括在系统时钟指示整个小时之间到达特定 operator 的所有记录。例如,如果应用程序在上午 9:15 开始运行,则第一个每小时处理时间窗口将包括在上午 9:15 到上午 10:00 之间处理的事件,下一个窗口将包括在上午 10:00 到 11:00 之间处理的事件。
处理时间是最简单的时间概念,不需要流和机器之间的协调。它提供最佳性能和最低延迟。但是,在分布式和异步环境中,处理时间不提供确定性,因为它容易受到记录到达系统的速度(例如从消息队列)到记录在系统内的 operator 之间流动的速度的影响,和停电(调度或其他)。
三类时间的区别总结

| EventTime | IngestTime | ProcessingTime | |
|---|---|---|---|
| 概念 | 事件生成时的时间,在进入 Flink 之前就已经存在,可以从 event 的字段中抽取。 | 事件进入 Flink 的时间,即在 source 里获取的当前系统的时间,后续操作统一使用该时间。 | 执行操作的机器的当前系统时间(每个算子都不一样) |
| 水位线 | 必须指定 watermarks(水位线)的生成方式。 | 不需要指定 watermarks 的生成方式(自动生成) | 不需要流和机器之间的协调 |
| 优点 | 确定性,乱序、延时、或者数据重放等情况,都能给出正确的结果 | 最佳的性能和最低的延迟 | |
| 缺点 | 处理无序事件时性能和延迟受到影响 | 不能处理无序事件和延迟数据 | 不确定性 ,容易受到各种因素影像(event 产生的速度、到达 flink 的速度、在算子之间传输速度等),压根就不管顺序和延迟 |
性能: ProcessingTime> IngestTime> EventTime
延迟: ProcessingTime< IngestTime< EventTime
确定性: EventTime> IngestTime> ProcessingTime
3.3、对于水位线的用处终极解释
前面提到了 watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用 watermark 机制结合 window 来实现。前面的时间机制已经提到,流处理从事件产生,到 source,再到 operator,中间是有一个过程的,并不是严格的实时。虽然大部分情况下,流到 operator 的数据都是按照事件产生的时间顺序进入 Flink 的,但是也不排除由于网络、背压等原因,导致乱序,而对于流中迟到的元素,Flink 又不能无限期等下去,所以必须要有个机制来保证一个特定的时间后,必须触发 window 去进行计算了。这个特别的机制,就是 watermark——水位线机制。
3.4、水位线解决乱序的原理
前面分析了,watermark 是用来解决乱序的,即保证一个特定时间后,必须触发 window 窗口计算,因此,可以根据事件的 event time,计算出水位线,并且设置一些延迟,给迟到的数据一些机会,也就是说正常来讲,对于迟到的数据,我只等你一段时间,再不来就没有机会了。
通过前面窗口机制概括,我们知道比如滚动窗口,或滑动窗口等,都有自己的触发机制,比如每隔 5 秒窗口就会计算(触发)一次。假如我们设置 10s 的时间窗口(window),那么 010s,1020s 都是一个窗口,以 0~10s 为例,0 是 start-time,10 是 end-time。假如有 4 个数据(ABCD),它们的 event-time 分别是 8(A),12.5(B),9(C),13.5(D),我们设置水位时间为当前所有到达数据的 event-time 的最大值减去延迟时间,这里延迟时间设置为 3.5s,也就是说对于迟到的数据,我们只等你 3.5 秒。【如果超过 3.5 秒该怎么办,这时候就需要我们对生产环境有一个整体的认识和把握,数据是否有延迟,延迟大概是多长时间,怎么样达到数据不丢失。当然还有另外的方法来处理延迟,这里只分析水位线的作用】。如下:
| 流中元素 | 事件时间(s) | 真正的到达顺序(并没严格按照事件时间进入 Flink) | 水位线(s) | 是否触发窗口计算(10s 的时间窗口) |
|---|---|---|---|---|
| A | 8 | A 到达 | max{8} - 3.5 = 8 - 3.5 = 4.5 | 否 |
| B | 12.5 | B 到达 | max(12.5, 8) - 3.5 = 12.5 - 3.5 = 9 | 否 |
| C | 9 | C 到达(迟到) | max(12.5, 8, 9) - 3.5 = 12.5 - 3.5 = 9 | 否 |
| D | 13.5 | D 到达 | max(13.5, 12.5, 8, 9) - 3.5 = 13.5 - 3.5 = 10 | 是 |
D 元素触发窗口计算的时候,会将 ABC(因为他们都小于 10)都计算进去,通过上面这种方式,就将迟到的 C 计算进去了,这样一来,watermark 可以在数据无序传递的时候有一定容错率,如果晚来的数据在容错范围之内,会当做正常传递来处理。
3.5、水位线不是万能的
3.4 里的延迟 3.5s 是假设一个数据到达的时候,比他早 3.5s 的数据肯定也都到达了,这个是需要根据经验推算的,假设 D 到达以后,又到达了一个 E,其 event-time=6,但是由于 0~10 的时间窗口已经开始计算了,所以 E 就丢了,E 的丢失说明水位线机制不是万能的,但是如果根据我们自己的生产经验 + 侧道输出等方案,可以做到数据不丢失。这又是一个新话题了,以后分析。