监控告警
1.监控
1.1 监控的目的
- 了解业务量级增长
- 感知系统健康度
- 告警 -> 及时发现问题
可用性量化: MTTF, MTTR, SLA, SLO
1.2 好的监控体系应该做到哪些?
- 指标全面,但不冗余.
- 报警敏感,但不误报
- 自动发现问题,以及分析原因
1.3 监控指标
USE (Utilization Saturation and Errors): 将注意力集中在处理工作负载的资源上。目标是了解这些资源在存在负载时的行为方式。
- 使用率,表示资源用于服务的时间或容量百分比。100% 的使用率,表示容量已经用尽或者全部时间都用于服务。
- 饱和度,表示资源的繁忙程度,通常与等待队列的长度相关。100% 的饱和度,表示资源无法接受更多的请求。
- 错误数表示发生错误的事件个数。错误数越多,表明系统的问题越严重。
RED(Request Throughput,Error Rate, Duration Time): 它是由资源提供服务的工作负载行为的外部可见视图
四个黄金信号: 延迟(Latency),流量(Traffic),错误(Errors)和 饱和度(Saturation)
1.4 监控体系
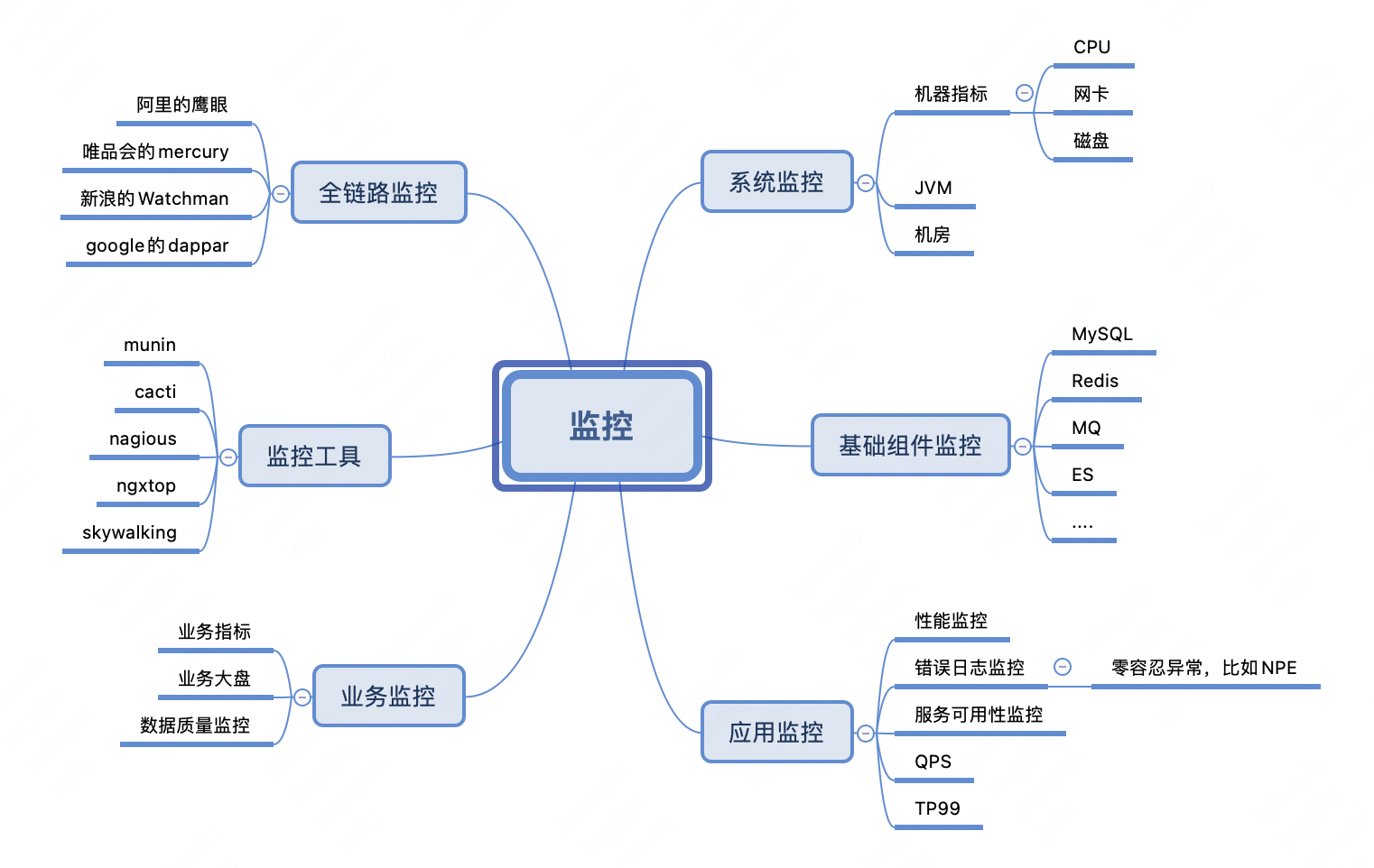
需要关注的点非常多(机器指标、数据库监控、接口性能、业务指标、异常日志等等),越想越多,越理越乱。 所以需要分层监控。
2.告警
目标: 避免误报、 漏报
2.1 报警级别规范
每一条告警都有自己的级别,大部分公司对告警分级都有设定,例如某司对告警的级别设定为: P0、P1、P2、P3。不同的告警级别代表通知范围不同、处理紧急度不同。
| 告警级别 | 告警含义 | 通知速度 | 响应速度 | 误报概率 |
|---|---|---|---|---|
| P0 | 大事故的发生,需马上处理 | 电话 + 短信 + ** + 邮件 | 第一时间做出响应并处理,响应时间 <=10 分钟 | 0 误报,告警意味着严重的事故 100% 发生 |
| P1 | 核心路径有波动,需马上处理 | 短信 + ** | 收到报警之后立即响应,响应时间 <=30 分钟 | 0 误报,告警意味着核心接口服务不稳定,有事故或有抖动 |
| P2 | 服务有波动,需关注 | ** | 观察系统指标,快速处理,响应时间 <=1 小时 | 允许少量误报 |
| P3 | 服务异常信息通知 | ** | 尽快处理 | 允许少量误报 |
对于不同级别的告警一般是这么进行区分:
- 不同阈值相同持续时间。 比如一分钟内 500 次异常定为 P1、1000 次异常定为 P0
- 相同阈值不同持续时间。 比如 P2 报警持续 5 分钟升级为 P1、P1 报警持续 5 分钟升级为 P0
2.2 告警治理
保证告警精准触达用户,通过技术手段、数据运营,减少冗余告警,提升告警有效性。
2.3 最佳实践
- 配置有效的告警,需要分析指标特征来对症下药,避免一刀切,千篇一律。
- 突增突降类指标的监控,需要先定义出“什么是异常?”,再针对异常进行监控,避免直接对原始的、不稳定的指标进行监控告警。
- 告警分优先级配置时,针对不同优先级侧重点不同,高优告警侧重于准确且及时,低优告警可接受一定的延迟,换取更低的误告警。
- 告警分时段配置时,不同时段侧重点不同。低频时段阈值宽松处理(避免大量误告警)、高频时段调小检测窗口严格处理(强调灵敏性)。
- 对于普适性的指标(Host、中间件等)告警配置,尽可能使用模板进行批量配置,以减少工作量,提升配置可维护性
- 对于不稳定的指标需进行归一化处理,转换为稳定指标(错误量 → 错误率),提升告警配置的有效性。
- 对于告警配置项,尽可能使用相对类配置(如波动百分比、基于基线的百分比等等),避免直接以某个固定值为基础进行比较配置。
- 监控做加法,告警做减法:监控开发是可以对系统从下而上,全面的进行监控,因为业务、系统是不断变化的,先期全面的监控能减少后续查漏补缺时的开发工作,并且更加全面丰富的监控指标有助于定位线上故障。但是在配置告警策略时,则应该提取当前关键核心的监控指标,来配置告警策略,减少无效告警数量。
难点: 接口差异,很难通用
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 WBINGのBLOG!
评论