PRC核心原理四
RPC 是解决分布式系统通信问题的一大利器,而分布式系统的一大特点就是高并发,所以说 RPC 也会面临高并发的场景。在这样的情况下,我们提供服务的每个服务节点就都可能由于访问量过大而引起一系列的问题,比如业务处理耗时过长、CPU 飘高、频繁 Full GC 以及服务进程直接宕机等等。但是在生产环境中,我们要保证服务的稳定性和高可用性,这时我们就需要业务进行自我保护,从而保证在高访问量、高并发的场景下,应用系统依然稳定,服务依然高可用。
那么在使用 RPC 时,业务又如何实现自我保护呢?
我们可以将 RPC 框架拆开来分析,RPC 调用包括服务端和调用端,调用端向服务端发起调用。下面我就分享一下服务端与调用端分别是如何进行自我保护的。
服务端的自我保护
我们先看服务端,作为服务端接收调用端发送过来的请求,这时服务端的某个节点负载压力过高了,我们该如何保护这个节点?如下图所示例:
负载压力高,那就不让它再接收太多的请求就好了,等接收和处理的请求数量下来后,这个节点的负载压力自然就下来了。在 RPC 调用中服务端的自我保护策略就是限流。
限流
限流是一个比较通用的功能,我们可以在 RPC 框架中集成限流的功能,让使用方自己去配置限流阈值;我们还可以在服务端添加限流逻辑,当调用端发送请求过来时,服务端在执行业务逻辑之前先执行限流逻辑,如果发现访问量过大并且超出了限流的阈值,就让服务端直接抛回给调用端一个限流异常,否则就执行正常的业务逻辑。
限流逻辑的实现
方式有很多,比如最简单的计数器,还有可以做到平滑限流的滑动窗口、漏斗算法以及令牌桶算法等等。其中令牌桶算法最为常用。
令牌桶算法
下图是令牌桶算法流程图:
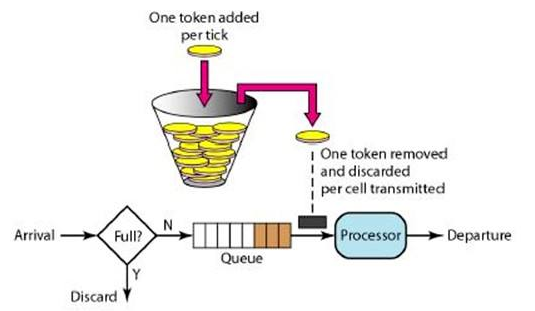
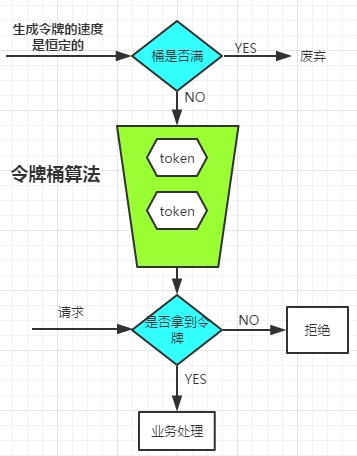
系统会按照固定是速度生成令牌(可配置),通过配置令牌生成速度的大小来起到对请求大小的限流作用。
生成的令牌放入桶中,如果桶中令牌满了,则令牌废弃。
每次请求来,都需要从桶中拿令牌,如果桶中有令牌,则进行业务处理,否则就会被拒绝。
从这里看出,业务的请求速度,如果小于令牌的生成速度,那么业务都会拿到令牌,则不会被拒绝。如果业务的请求速度大于令牌的生成速度,则可能桶中没有了令牌,拿不到令牌而被拒绝。
所以令牌的生成速度大小可以起到对请求速度限流的调节作用。
动态配置限流
通常我们在做限流的时候要考虑应用级别的维度,甚至是 IP 级别的维度,这样做不仅可以让我们对一个应用下的调用端发送过来的请求流量做限流,还可以对一个 IP 发送过来的请求流量做限流。
RPC 框架真正强大的地方在于它的治理功能,而治理功能大多都需要依赖一个注册中心或者配置中心,我们可以通过 RPC 治理的管理端进行配置,再通过注册中心或者配置中心将限流阈值的配置下发到服务提供方的每个节点上,实现动态配置。
看到这儿,你有没有发现,在服务端实现限流,配置的限流阈值是作用在每个服务节点上的。比如说我配置的阈值是每秒 1000 次请求,那么就是指一台机器每秒处理 1000 次请求;如果我的服务集群拥有 10 个服务节点,那么我提供的服务限流阈值在最理想的情况下就是每秒 10000 次。
另外我们也可以让 RPC 框架自己去计算,当注册中心或配置中心将限流阈值配置下发的时候,我们可以将总服务节点数也下发给服务节点,之后由服务节点自己计算限流阈值。
我们还可以提供一个专门的限流服务,让每个节点都依赖一个限流服务,当请求流量打过来时,服务节点触发限流逻辑,调用这个限流服务来判断是否到达了限流阈值。我们甚至可以将限流逻辑放在调用端,调用端在发出请求时先触发限流逻辑,调用限流服务,如果请求量已经到达了限流阈值,请求都不需要发出去,直接返回给动态代理一个限流异常即可。
这种限流方式可以让整个服务集群的限流变得更加精确,但也由于依赖了一个限流服务,它在性能和耗时上与单机的限流方式相比是有很大劣势的。至于要选择哪种限流方式,就要结合具体的应用场景进行选择了。
这些方法都是为了让RPC框架能自我识别流量,自动调整限流策略,降低因人为预估的不准确而造成系统的稳定性降低。
调用端的自我保护
在微服务中由于多个服务的调用关系,当一个服务 A 来调用服务 B 时,服务 B 的业务逻辑调用服务 C,而这时服务 C 响应超时了,由于服务 B 依赖服务 C,C 超时直接导致 B 的业务逻辑一直等待,而这个时候服务 A 在频繁地调用服务 B,服务 B 就可能会因为堆积大量的请求而导致服务宕机。
由此可见,服务 B 调用服务 C,服务 C 执行业务逻辑出现异常时,会影响到服务 B,甚至可能会引起服务 B 宕机。这还只是 A->B->C 的情况,试想一下 A->B->C->D->……呢?在整个调用链中,只要中间有一个服务出现问题,都可能会引起上游的所有服务出现一系列的问题,甚至会引起整个调用链的服务都宕机,这就是我们经常遇到的一种服务雪崩情况。
所以说,在一个服务作为调用端调用另外一个服务时,为了防止被调用的服务出现问题而影响到作为调用端的这个服务,这个服务也需要进行自我保护。而最有效的自我保护方式就是熔断和降级。
熔断
通过熔断器的打开/关闭来判断是否对下游进行服务的调用。
熔断机制
而熔断器的打开和关闭由熔断机制决定。这个机制参考的是电路中保险丝的保护机制,当电路超负荷运转的时候,保险丝会断开电路,保证整体电路不受损害。而服务治理中的熔断机制指的是在发起服务调用的时候,如果返回错误或者超时的次数超过一定阈值,则后续的请求不再发向远程服务而是暂时返回错误。
这种实现方式在云计算领域又称为断路器模式,在这种模式下,服务调用方为每一个调用的服务维护一个有限状态机,在这个状态机中会有三种状态:关闭(调用远程服务)、半打开(尝试调用远程服务)和打开(返回错误)。这三种状态之间切换的过程是下面这个样子。
- 当调用失败的次数累积到一定的阈值时,熔断状态从关闭态切换到打开态。一般在实现时,如果调用成功一次,就会重置调用失败次数。
- 当熔断处于打开状态时,我们会启动一个超时计时器,当计时器超时后,状态切换到半打开态。你也可以通过设置一个定时器,定期地探测服务是否恢复。
- 在熔断处于半打开状态时,请求可以达到后端服务,如果累计一定的成功次数后,状态切换到关闭态;如果出现调用失败的情况,则切换到打开态。
降级
除了熔断之外,我们听到最多的服务容错方式就是降级,那么降级又是怎么做的呢?它和熔断有什么关系呢?
其实在我看来,相比熔断来说,降级是一个更大的概念。因为它是站在整体系统负载的角度上,放弃部分非核心功能或者服务,保证整体的可用性的方法,是一种有损的系统容错方式。这样看来,熔断也是降级的一种。
开关降级指的是在代码中预先埋设一些“开关”,用来控制服务调用的返回值。比方说,开关关闭的时候正常调用远程服务,开关打开时则执行降级的策略。这些开关的值可以存储在配置中心中,当系统出现问题需要降级时,只需要通过配置中心动态更改开关的值,就可以实现不重启服务快速地降级远程服务了。
还是以电商系统为例,你的电商系统在商品详情页面除了展示商品数据以外,还需要展示评论的数据,但是主体还是商品数据,在必要时可以降级评论数据。所以,你可以定义这个开关为“degrade.comment”,写入到配置中心中,具体的代码也比较简单,就像下面这样:
1 | boolean switcherValue = getFromConfigCenter("degrade.comment"); //从配置中心获取开关的值 |
当然了,我们在设计开关降级预案的时候,首先要区分哪些是核心服务,哪些是非核心服务。因为我们只能针对非核心服务来做降级处理,然后就可以针对具体的业务,制定不同的降级策略了。我给你列举一些常见场景下的降级策略,你在实际的工作中可以参考借鉴。
- 针对读取数据的场景,我们一般采用的策略是直接返回降级数据。比如,如果数据库的压力比较大,我们在降级的时候,可以考虑只读取缓存的数据,而不再读取数据库中的数据;如果非核心接口出现问题,可以直接返回服务繁忙或者返回固定的降级数据。
- 对于一些轮询查询数据的场景,比如每隔 30 秒轮询获取未读数,可以降低获取数据的频率(将获取频率下降到 10 分钟一次)。
- 而对于写数据的场景,一般会考虑把同步写转换成异步写,这样可以牺牲一些数据一致性保证系统的可用性。
我想强调的是,只有经过演练的开关才是有用的开关,有些同学在给系统加了开关之后并不测试,结果出了问题真要使用的时候,却发现开关并不生效。因此,你在为系统增加降级开关时,一定要在流量低峰期的时候做验证演练,也可以在不定期的压力测试过程中演练,保证开关的可用性。
RPC系列总结
通过这四章,讲解了RPC的核心原理,其中因为微服务架构的兴起,我们对RPC框架也有了更高的要求,如服务发现,服务治理,限流,熔断降级等。而微服务让服务拆分,一个请求调用关系可能会很复杂,所以在微服务架构中,通常还需要有分布式Trace链路跟踪、业务分组流量隔离机制等。这些因为对于RPC来说只是信息传递能力,所以在RPC章节就不再讲解,后续可能会在微服务中再重点讲解。