ES最佳实践
集群配置最佳实践
1.磁盘选择
- 尽可能使用使用 SSD,ES 最大的瓶颈往往是磁盘读写性能,SSD 要比 SATA 查询快 5-10 倍,所以查询要求高的业务建议选择 SSD 或者 PCIE,查询要求不那么高的业务可以选择 SATA
- 对于数据节点建议使用单机器 500G 以上的磁盘
- 对于协调节点,200G 足矣,协调节点不存数据,只做转发和聚合
2.内存选择
- 尽可能选择 16G 以上,由于 ES 的段文件(索引文件)存储在缓存中,尽量满足所有的段文件都存在缓存中,提高查询的效率
- ES JVM 配置机器一半的内存,但是不要超过 32G
- 内存和磁盘 1:10
3.集群角色配置
- 数据节点和协调节点隔离,避免协调节点因数据问题 down 机之后导致整个集群崩溃
- 集群尽量配置固定数量的协调节点(一般 3 个足矣),数据节点可以扩展
4.分片和副本设置
- 每个数据节点上都尽量分配某个索引的一个分片,使数据足够均匀
- 每个索引分片不要超过 30G
- 单节点数据控制再 2T 以内
5.调大 refresh interval 调高
ES 的 refresh 操作:是将 index-buffer 中文档(document)解析完成的 segment 写到 filesystem cache 中的过程
ES 默认每个分片每秒钟都会进行一次 refresh,刷新的过程其实就是文档从索引到被搜索的过程,刷新后会生成新的段,这会产生大量的段文件
如果业务对数据的实时性要求不高,可以调高
1
2
3
4
5
6
7PUT /twitter/_settings
{
"index":{
"refresh_interval":"1s"
}
}
6.translog 同步改异步
translog 的作用是用于恢复数据,数据在被索引之前会被先加入至 translog 中,默认情况下 translog 是每写一次就刷盘一次,可以改成异步刷新
1 | PUT /my_index/_settings |
7.定期进行段文件合并
注意 ES 得索引倒排索引文件是存在 segment 中,segment 是存在内存中,由于每次 refresh 都会生产新的 segment,如果 segment 过多会消耗较大内存,定期进行段合并有几个好处
- 减少内存消耗
- 加快查询性能,每次搜索请求都需要依次检查每个段。段越多,查询越慢。
- 合并段的同时会把释放已删除的索引空间,业务如果使用 delete by id 进行索引删除,es 只是把数据标记为已删除,并没有释放空间,在segment 合并时会把这些数据进行清理
如下:这里的max_num_segments 是希望最终合并成多少个段
POST /twitter/_forcemerge/max_num_segments=1
8.使用索引模板
如果索引未来的增长比较快,并且存在明显的 冷热区分(旧索引访问热度低或者无访问),那烦请使用索引模板,按日期方式创建,索引,这样对应旧索引可以方便的删除或者隔离
写入配置最佳实践
一、索引模板的使用
1.1 评估是否需要模板
在新建一个索引之前,要判断索引未来的数据变化趋势,如果索引数据量是固定的,那可以不使用模板,如果未来数据会不断增加,那强烈建议使用模板定期创建索引
- 模板的使用可以减少每次创建索引的成本
- 定期创建索引可以有效减少单个索引的大小,利于后续对历史数据清理和归档,以及做数据冷热隔离
- 同时小索引比较容易迁移数据
1.2 基于时间创建索引
- 按照月份或者年份或者天来创建索引
- 确保单个分片不要超过 20G,一半单个索引 5 个分片,也就是最好索引不要超过 100G,业务根据数据增量情况确定创建索引的时间周期
二、索引 Mapping 设计
2.1 Schema 设计
- 尽管 Elasticsearch 支持半结构化数据,但是在实际使用中还是应该尽最大可能对数据结构加以控制。
- 因为 Elasticsearch 不支持 JOIN 操作,所以 Schema 应该尽量扁平化,减少嵌套。
- 对于只需要做精确匹配的字段,应该设置为不做分词,避免使用 text 类型,5.5 以上得版本中通过 type=keyword 来设定。
- 如果字段类型无需排序以及分词,使用 keyword 性能更好
2.2 参数设定
index.mapping.total_fields.limit:一个索引中能定义的字段的最大数量,默认是 1000
index.mapping.depth.limit:字段的最大深度,以内部对象的数量来计算,默认是 20
index.mapping.nested_fields.limit:索引中嵌套字段的最大数量,默认是 50
_source 字段:如果_source=true,Elasticsearch 会将整个 JSON 数据也存储下来。如果你的业务中,不需要查询原始数据,只需要根据索引来过滤然后做聚合查询,那么可以将其设置为 false,同样可以节省磁盘空间、提高性能。
dynamic 字段:strict,true,false
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17PUT /my_index
{
"mappings":{
"my_type":{
"dynamic":"strict",
"properties":{
"title":{
"type":"string"
},
"stash":{
"type":"object",
"dynamic":true
}
}
}
}
}
三、别名用法
3.1 无缝切换索引
在查询数据时,Elasticsearch 会自动检测请求的 Path 是否是 Alias,是的话就会从其关联的 Index 中查询数据,并且做到无缝切换,客户端无感知,对于新老索引的切换非常适用
3.2 良好的数据扩展性
一个别名可以对应多个索引,指定别名查询便可以满足多个索引中的数据查询,对于按时间创建索引得场景非常试用
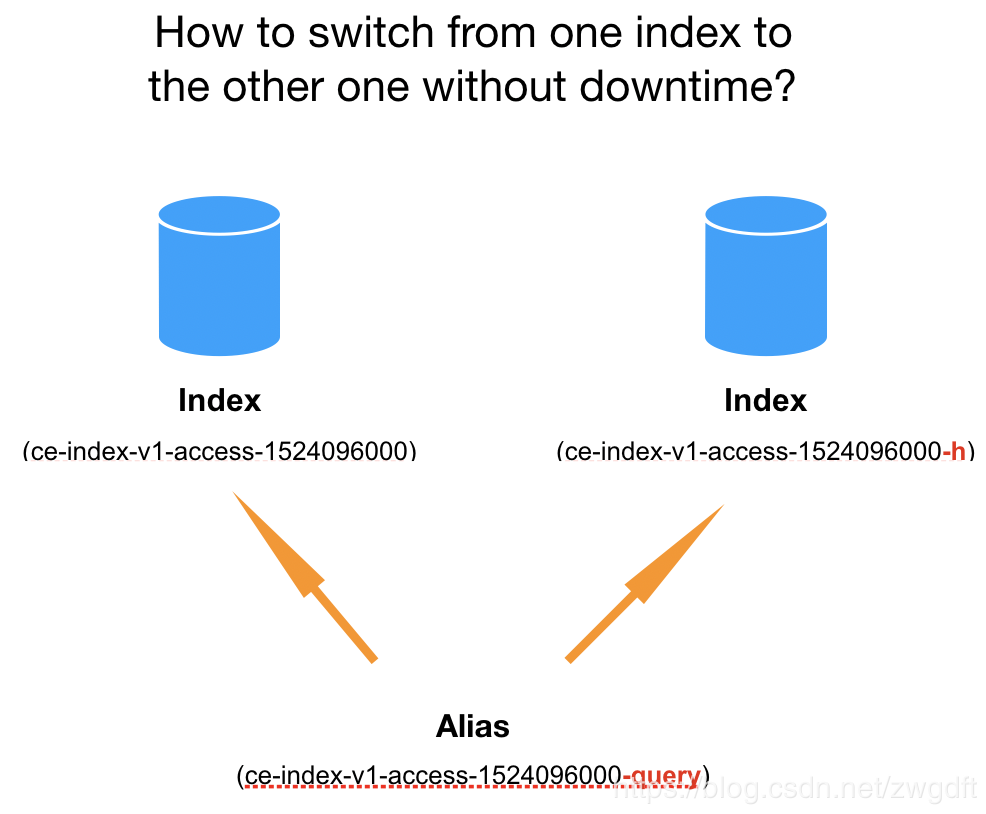
四、数据写入磁盘过程
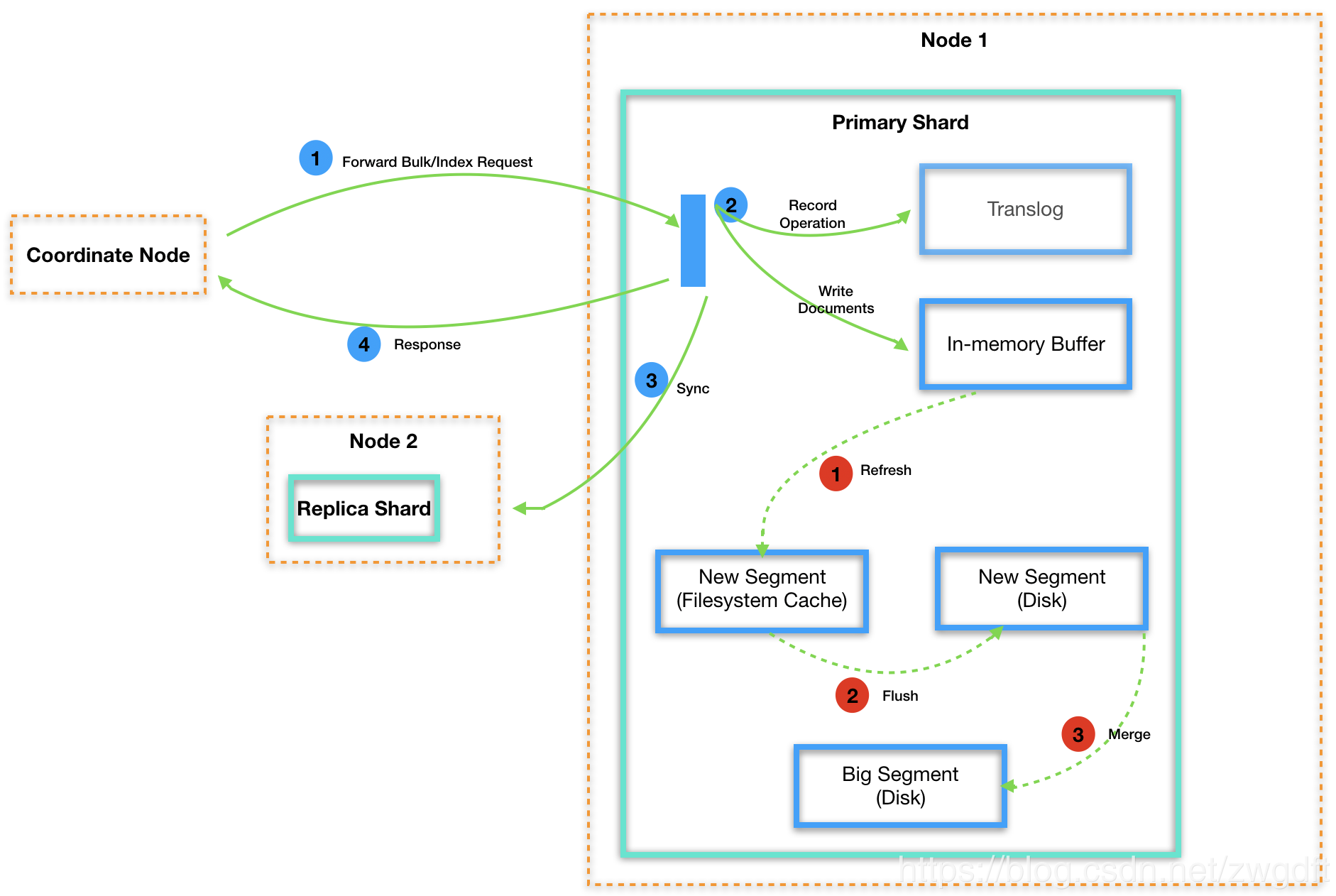
五、写入索引配置建议
bulk 写入,但是要控制写入的量,一次性不能过多,尽量先压测,建议每批提交 5-15M 的数据
尽量使用 es 自动生成的document id,
增加 refresh 间隔,如果在写入期间对实时性要求不高,可以增加 refresh 的间隔
1
2
3
4
5
6PUT /twitter/_settings
{
"index":{
"refresh_interval":"1s"
}
}
4.写入期间将副本数设置为 0,写完后再修改副数可以提高写入效率
5.适当增加 index buffer 的值,如上图,写入期间,数据会先缓存在 index buffer 中,然后再定期 flush 到磁盘,所以适当增加这个 buffer 得值,也能提高写入效率,indices.memory.index_buffer_size:15%,该值在 elasticsearch.yml 中设置
6.副本数量不建议太大,因为写入数据后,主分片要同步数据至副本会消耗大量 IO,影响写的性能。
查询配置最佳实践
1、字段类型选择
- 字符串类型,如果需要分词则选择 text,会对每个词建立倒排索引,存储成本较高,所以无需分词得情况请使用 keyword
- 数值类型,尽量选择贴合实际数值大小得类型,比如价格,使用 float 或者 double,不需要范围查询尽量使用可我、yword
2、查询语句使用
避免使用嵌套类型,nested 或者 object,使用嵌套类型性能会慢 10 几倍,尽量把逻辑处理放在客户端代码
避免使用父子关系,parent-child,使用父子类型性能会慢百倍以上
控制返回结果集,size 不要超过 1000,这是引发 full gc 常见得原因
严禁使用通配符,比如es
避免使用查询时的 script 计算
尽量使用 query-bool-filter, filter 的缓存机制会使的检索更快
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17GET /_search
{
"query":{
"filtered":{
"query":{
"match":{
"email":"business opportunity"
}
},
"filter":{
"term":{
"folder":"inbox"
}
}
}
}
}控制聚合的数量,减少内存的开销
控制返回字段,_source 过滤,只返回业务相关的字段,减少 IO 开销,如下,搜索返回结果中希望包含 obj1 核 obj2 开头得字段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16{
"query":{
"filtered":{
"query":{
"match":{
"email":"business opportunity"
}
},
"filter":{
"term":{
"folder":"inbox"
}
}
}
}
}9.避免在高峰期进行段文件合并,段文件合并会消耗大量 IO,影响查询和读写