标签数据存储在Hbase中,为了加速标签探索功能,会每天导出一份全量数据表。有时候用户也会进行特定标签勾选导出需求。
导出遇到的问题
导出后,出现部分用户,同一个用户多条数据(两条为主),见下图: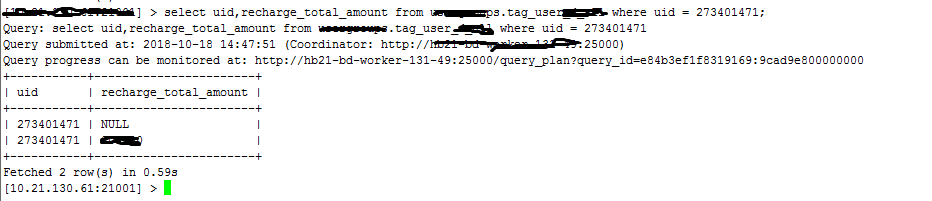

从图中可以看出,出现了重复用户uid。
问题原因
首先想到会不会是源数据问题,即Hbase中存储的数据造成的。为何如此想,是因为为了用户scan并发度和热点问题,对rowkey进行了hash(uid)分区。会不会在之前hash方法有变化,造成了脏数据问题。这点个人想了下,貌似也没变过hash函数啊,不应该出现uid hash后出现不同值啊。
然后对重复的uid随机抽取了几个,查看了数据情况。发现重复的uid的标签数据,标签总是错开的,即第一条数据有标签A;B;C,第二条A;B;C数据为空,而其他标签数据存在。这是一个突破口,思考会不会在导出的过程中,同一个用户的标签并截成了两段,出现了两天数据。为什么如此,这个需要简单介绍下在使用spark程序导出Hbase存储的标签的code。
1 | val hbaseCols = hBaseContext.hbaseRDD(TableName.valueOf(hbase_table), scan, (r: (ImmutableBytesWritable, Result)) => { |
其中Result类是Hbase client读取Hbase中数据,内部是cell数组形式,ImmutableBytesWritable中存储了数据行的rowkey。所以返回的(ImmutableBytesWritable, Result)便是封装了(rowkey,List
1 | val scan = new Scan() |
而问题的来源在于scan.setBatch(1000000),当时设置Batch,为了通过一次scan达到一定量后在返回,起到减少RPC的作用,加快数据导出。在Hbase API查询时,能够通过next()调用获取数据,而通过batch减少client与server见的RPC调用。
1 | /** |
batch的注释说明每次调用next()返回的最大value个数。
而spark-hbase模式,是通过InputFormat直接访问底层数据,然后转换成rdd数据。而设置了batch,同样会让读取的列数达到batch数目时做截断,这可能就造成某些行的列数据被拆分成了不同的batch,也就造成了同一个用户数据变成了两行数据。
Hbase batch与caching
每一个next()调用都会为每行数据生成一个单独RPC请求,即使使用next(int nbRows)方法,也是如此,因为该方法仅仅是在客户端循环地调用next()方法。很显然,当单元格数据较小时,这样做的性能不会很好。因此,如果一次RPC请求可以获取多行数据,这样更会有意义。这样的方法可以由扫描器缓存实现,默认情况下,这个缓存是关闭的。
setScannerCaching()可以设置缓存大小,getScannerCaching()可以返回当前缓存大小的值。每次用户调用getScanner(scan)之后,API都会把设定值配置到扫描实例中——除非用户使用了扫描层面的配置并覆盖了表层面的配置,扫描层面的配置优先级最高。可以使用下列Scan类方法设置扫描级的缓存:
1 | void setScannerCaching(int scannerCaching) |
如果对于数据量非常大的行,这些行很有可能超过客户端进程的内存容量。HBase和它的客户端API对这个问题有一个解决方法:批量。用户可以使用以下方法控制获取批量操作:
1 | void setBatch(int batch) |
缓存是面向行一级的操作,而批量是面向列一级的操作。批量可以让用户选择每一次ResultScanner()实例的next()操作要取回多少列。
**如果一行包括的列数超过了批量中设置的值,则可以将这一行分片,每次next操作返回一片。 **
这样便可以通过caching和batch来影响RPC次数。下表展示了不同caching和batch的RPC次数,其他一行的列数为20:
|缓存| 批量处理| Result个数| RPC次数| 说明|
|—–|—–|—–|—–|
|1| 1| 200| 201| 每个列都作为一个Result实例返回。最后还多一个RPC确认扫描完成|
|200| 1| 200| 2| 每个Result实例都只包含一列的值,不过它们都被一次RPC请求取回|
|2| 10| 20| 11| 批量参数是一行所包含的列数的一半,所以200列除以10,需要20个result实例。同时需要10次RPC请求取回。|
|5| 100| 10| 3| 对一行来讲,这个批量参数实在是太大了,所以一行的20列都被放入到了一个Result实例中。同时缓存为5,所以10个Result实例被两次RPC请求取回。|
|5| 20| 10| 3| 同上,不过这次的批量值与一行列数正好相同,所以输出与上面一种情况相同|
|10| 10| 20| 3| 这次把表分成了较小的result实例,但使用了较大的缓存值,所以也是只用了两次RPC请求就返回了数据|
问题解决
找到原因了,解决方法也简单,将setBatch()去掉即可。重新导出,不在出现重复的uid数据了。