1. 从机器学习到百模大战
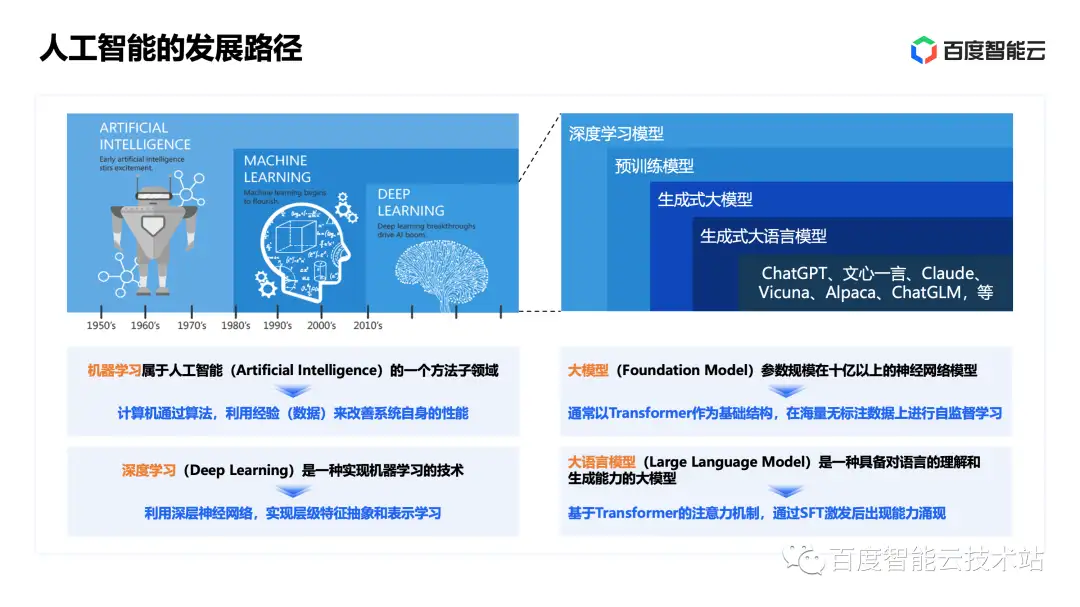
众所周知,目前我们实现人工智能的主要技术手段是机器学习技术,特别是其中基于深层神经网络的深度学习技术。机器学习的本质是通过具有学习能力的算法、对数据进行建模的技术。深度学习借助大规模的算力解决了机器学习中特征表示的人工干预的瓶颈,在效果上取得了巨大突破。因此,机器学习成为目前人工智能的主流技术。
深度学习和生成式大模型之间的关系,如下图右侧所示,在 2012 年至 2016 年左右,像卷积神经网络、对抗生成网络、ResNet 等经典的深度学习模型,已经在计算视觉、语音识别、自然语言处理等领域取得了显著的效果提升。这些经典深度学习模型既有判别式、也有生成式,它们往往会在 ImageNet、COCO 等有标注的数据集上进行预训练,形成带有预训练权重、可以进一步进行 Fine-tuning 的预训练模型。
在 2017 年之后,Transformer 结构在自然语言处理领域首先被成功应用,在这之后以 Transformer 为基础组件的生成式大模型逐步成为视觉、自然语言处理、跨模态理解和生成领域的主流技术。这类技术通常以 Transformer 和注意力机制作为组件,并且它可以并行地进行自监督学习,参数规模在十亿以上。其中,将生成式大模型技术应用在语言建模上的方式,被称为「大语言模型」。在经过进一步的调优之后,形成了像 ChatGPT、文心一言等被大家熟知的对话式、生成式大语言模型应用。
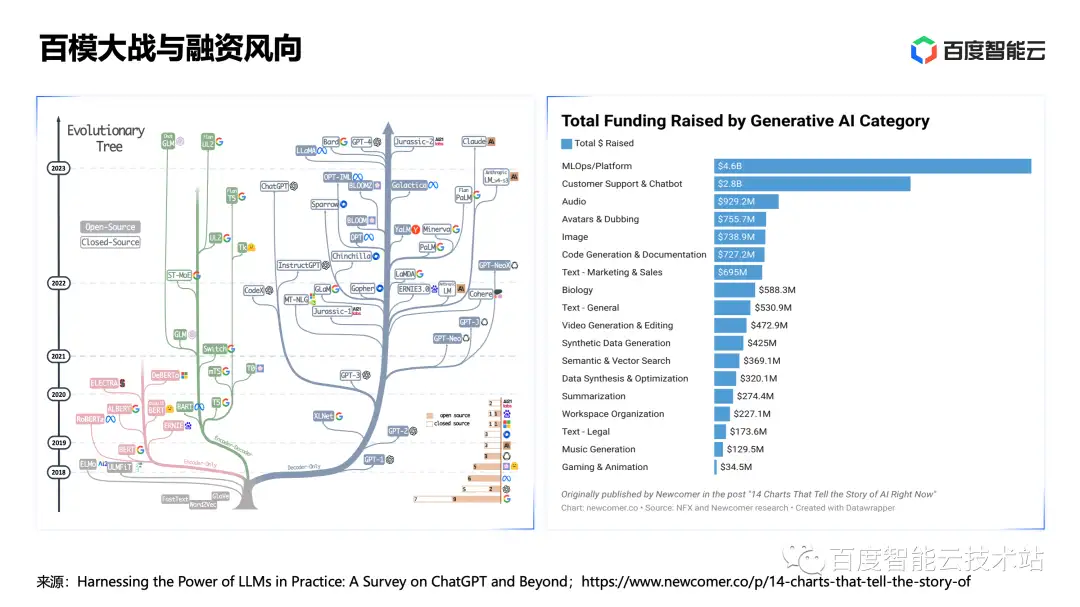
在过去的半年,我们经历了一场百模大战。尤其是在开源社区,新的大模型如雨后春笋般涌现,而大模型相关的技术也越来越标准化、同质化。在这里为大家分享一个小故事。我们可以在大模型中了解到很多「驼」系英语词汇,比如 Llama 是美洲驼,Alpaca 是羊驼,Vicuna 是小羊驼。
为什么有那么多以「驼」命名的大语言模型?因为大语言模型 Large Language Model 的缩写是 LLM,2 个 L 放在一起不方便读出来,Meta 公司为了方便大家记忆,所以选了相近的词语 Llama(美洲驼)。后来很多基于 Llama 开源模型进行调优和构建的大语言模型,都以「驼」系的名称命名。
如下图所示,我们可以看到在硅谷的大模型创业公司中,除 OpenAI 外,目前已有将近 1/3 的资金投入了 MLOps 和 LMOps 相关的平台和工具方向。接下来,我将为大家详细拆解,在百模大战的背后,为什么 MLOps 和 LMOps 平台和工具能够获得资本的青睐。
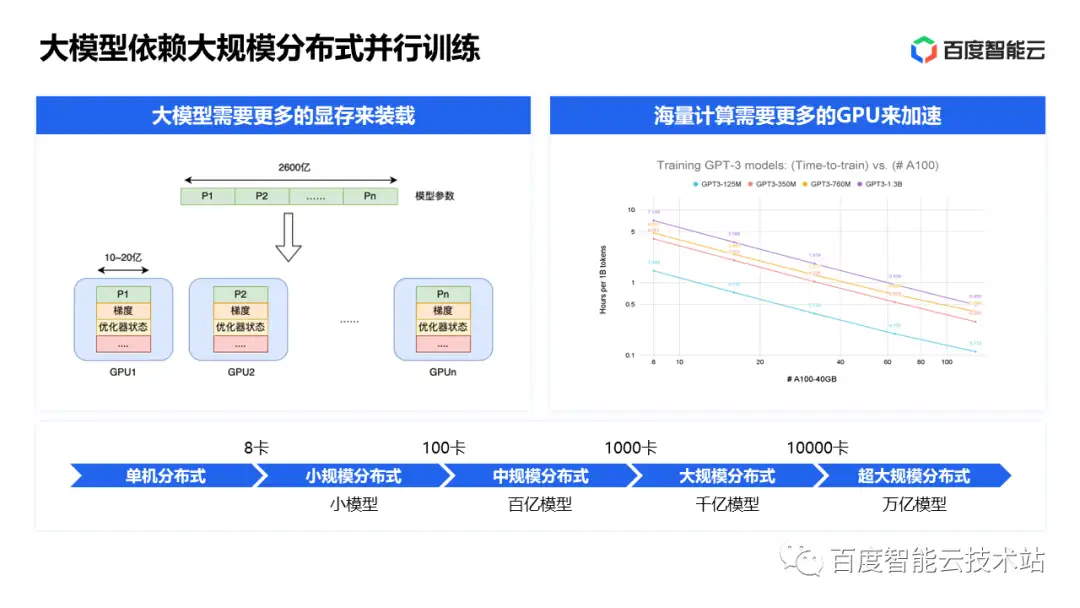
首先看看大模型在技术和应用层面带来了哪些变化。比如在以下 4 个技术层面: