snapshot(快照)基础原理
snapshot是很多存储系统和数据库系统都支持的功能。一个snapshot是一个全部文件系统、或者某个目录在某一时刻的镜像。实现数据文件镜像最简单粗暴的方式是加锁拷贝(之所以需要加锁,是因为镜像得到的数据必须是某一时刻完全一致的数据),拷贝的这段时间不允许对原数据进行任何形式的更新删除,仅提供只读操作,拷贝完成之后再释放锁。这种方式涉及数据的实际拷贝,数据量大的情况下必然会花费大量时间,长时间的加锁拷贝必然导致客户端长时间不能更新删除,这是生产线上不能容忍的。
snapshot机制并不会拷贝数据,可以理解为它是原数据的一份指针。在HBase这种LSM类型系统结构下是比较容易理解的,我们知道HBase数据文件一旦落到磁盘之后就不再允许更新删除等原地修改操作,如果想更新删除的话可以追加写入新文件(HBase中根本没有更新接口,删除命令也是追加写入)。这种机制下实现某个表的snapshot只需要给当前表的所有文件分别新建一个引用(指针),其他新写入的数据重新创建一个新文件写入即可。
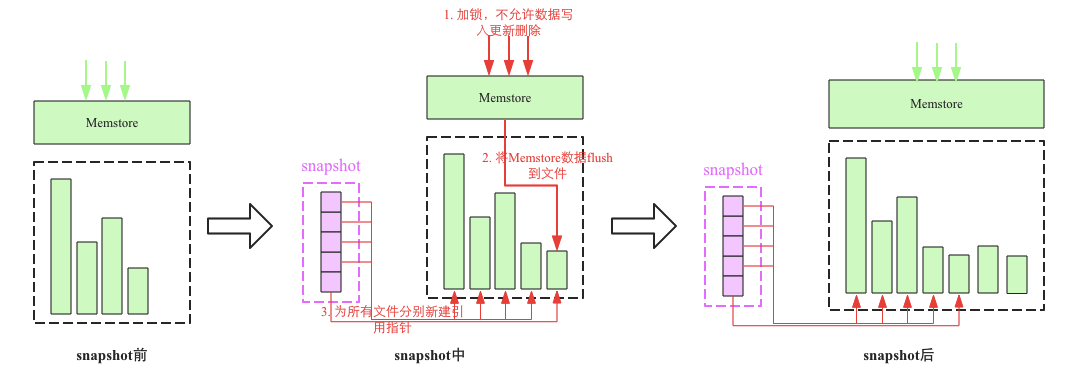
snapshot流程主要涉及3个步骤:
加一把全局锁,此时不允许任何的数据写入更新以及删除
将Memstore中的缓存数据flush到文件中(可选)
为所有HFile文件分别新建引用指针,这些指针元数据就是snapshot
snapshot作用
- 备份:通常情况下,对重要的业务数据,建议至少每天执行一次snapshot来保存数据的快照记录,并且定期清理过期快照,这样如果业务发生重要错误需要回滚的话是可以回滚到之前的一个快照点的。
- 迁移:可以使用ExportSnapshot功能将快照导出到另一个集群,实现数据的迁移
snapshot相关命令
snapshot最常用的命令有snapshot、restore_snapshot、clone_snapshot以及ExportSnapshot这个工具,具体使用方法如下:
为表’sourceTable’打一个快照’snapshotName’,快照并不涉及数据移动,可以在线完成。
1 | hbase> snapshot 'sourceTable', ‘snapshotName' |
恢复指定快照,恢复过程会替代原有数据,将表还原到快照点,快照点之后的所有更新将会丢失。需要注意的是原表需要先disable掉,才能执行restore_snapshot操作。
1 | hbase> restore_snapshot ‘snapshotName' |
根据快照恢复出一个新表,恢复过程不涉及数据移动,可以在秒级完成。
1 | hbase> clone_snapshot 'snapshotName', ‘tableName' |
使用ExportSnapshot命令可以将A集群的快照数据迁移到B集群,ExportSnapshot是HDFS层面的操作,会使用MR进行数据的并行迁移,因此需要在开启MR的机器上进行迁移。HMaster和HRegionServer并不参与这个过程,因此不会带来额外的内存开销以及GC开销。唯一的影响是DN在拷贝数据的时候需要额外的带宽以及IO负载,ExportSnapshot也针对这个问题设置了参数-bandwidth来限制带宽的使用。
1 | hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \ |
clone_snapshot的实现
在snapshot原理中,我们获知:snapshot并不会拷贝数据,而是维护原数据的一份指针。可能很多人会有一个疑惑,如果我把原数据删掉,snapshot是否就失效了,毕竟它只是一份指针。最开始我也是这样认为的,后来在自己误删除了原表,然后使用snapshot却将数据还原了,对此感到很不可思议。下面讲解下snapshot内部是如何做到的。
首先,进行了snapshot的表,在删除操作中,并不会真正的删除数据,而是将数据放入archive目录下。和普通表删除的情况不同的是,普通表一旦删除,刚开始是可以在archive中看到删除表的数据文件,但是等待一段时间后archive中的数据就会被彻底删除,再也无法找回。这是因为master上会启动一个定期清理archive中垃圾文件的线程(HFileCleaner),定期会对这些被删除的垃圾文件进行清理。但是snapshot原始表被删除之后进入archive,并不可以被定期清理掉,上文说过clone出来的新表并没有clone真正的文件,而是生成的指向原始文件的连接,这类文件称之为LinkFile,很显然,只要LinkFile还指向这些原始文件,它们就不可以被删除。
那么什么时候LinkFile会变成真实的数据文件?
HBase中一个region分裂成两个子region后,子region的文件也是引用文件(见HBase系列之region-split),这些引用文件是在执行compact的时候才真正将父region中的文件迁移到自己的文件目录下。LinkFile也一样,在clone出的新表执行compact的时候才将合并后的文件写到新目录并将相关的LinkFile删除,理论上也是借着compact顺便做了这件事。
所以当时我clone了新表出来后,我在region_server上查看HFile文件,看到了:
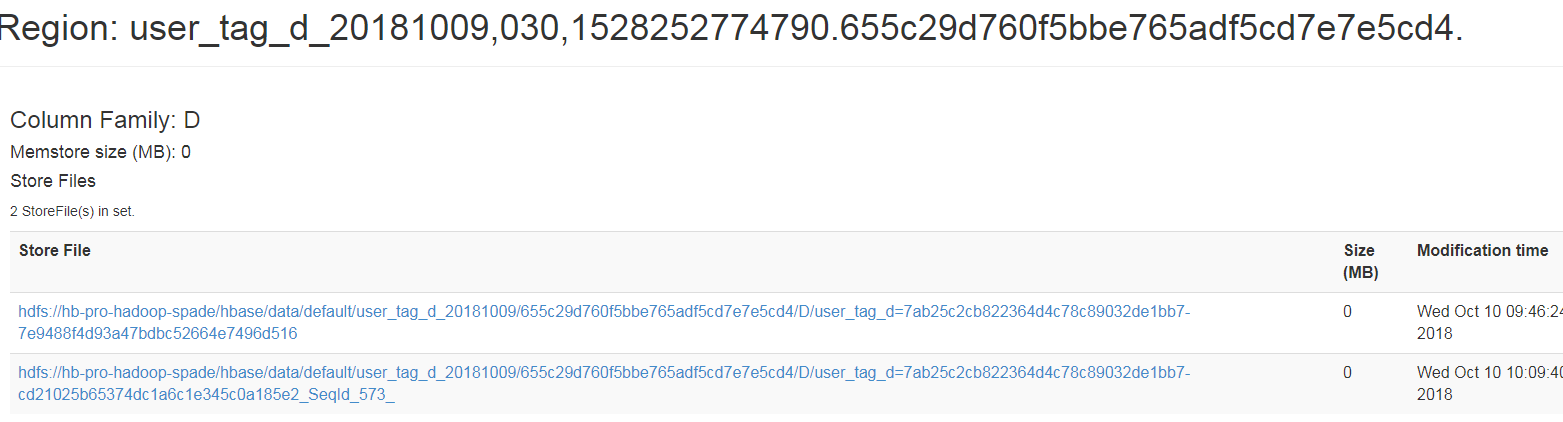
从图中可以看出,HFile为0,说明还没有HFile文件,但我在hbase shell中却能够get数据,现在知道HFile没有,而是通过LinkFile指向原始文件。如果想把生成HFile,怎么做呢?很简单,只需要进行让region进行compact,你可以不用管它,在进行插入数据而自动触发compact,也可以手动对新表执行major_compact操作:
1 | major_compact ’clone_table’ |
这样当compact执行完,你就可以在region_server上看到HFile了。