一、索引建立
1.1 数据类型
搜索的前提是索引已经建立好,ES 中的数据分为 2 类
- 精确值:如 id,ip 等,精确值只能精确匹配,适用于 term 查询,查询的时候是根据二进制来比较
- 全文:指文本内容,比如日志,邮件内容,url 等,适用于 match 查询,只能查出看起来像的结果
以下对五条 doc 建立索引
| Name | Age | Address |
|---|---|---|
| Alan | 33 | West Street Ca USA |
| Alice | 13 | East Street La USA |
| Brad | 19 | Suzhou JiangSu China |
| Alice | 15 | Nanjing JiangSu China |
| Alan | 11 | Changning Shanghai China |
1.2 索引建立流程
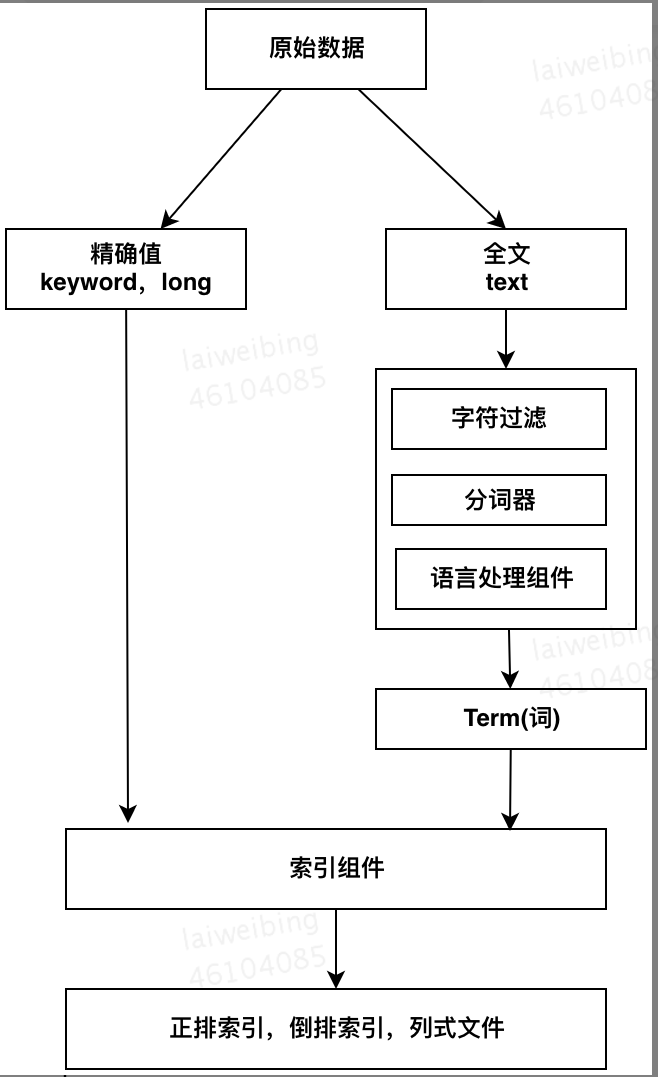
索引结构如下:
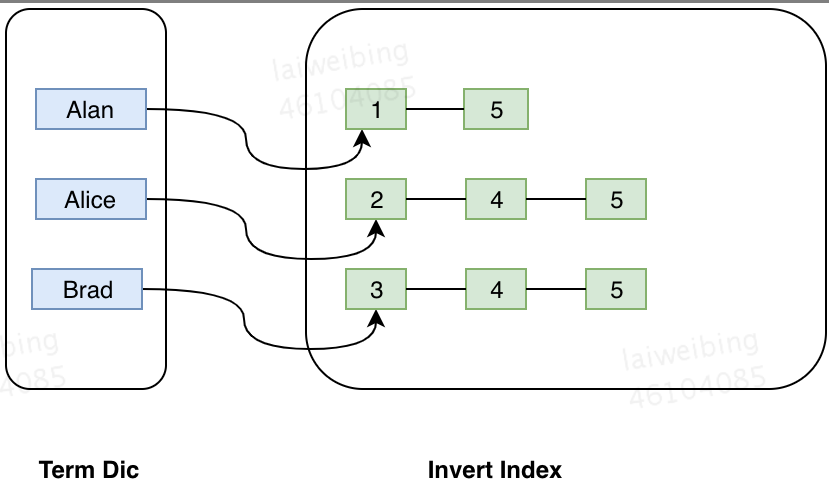
二、执行搜索
- 如果是精确值搜索,比如搜索 Id 为 20002,直接去正排和倒排索引中查找匹配的文档
- 如果是全文查询,则需要先对检索内容进行分析,产生 token 词条,再根据 token 词条去正排和倒排索引中匹配相应的文档
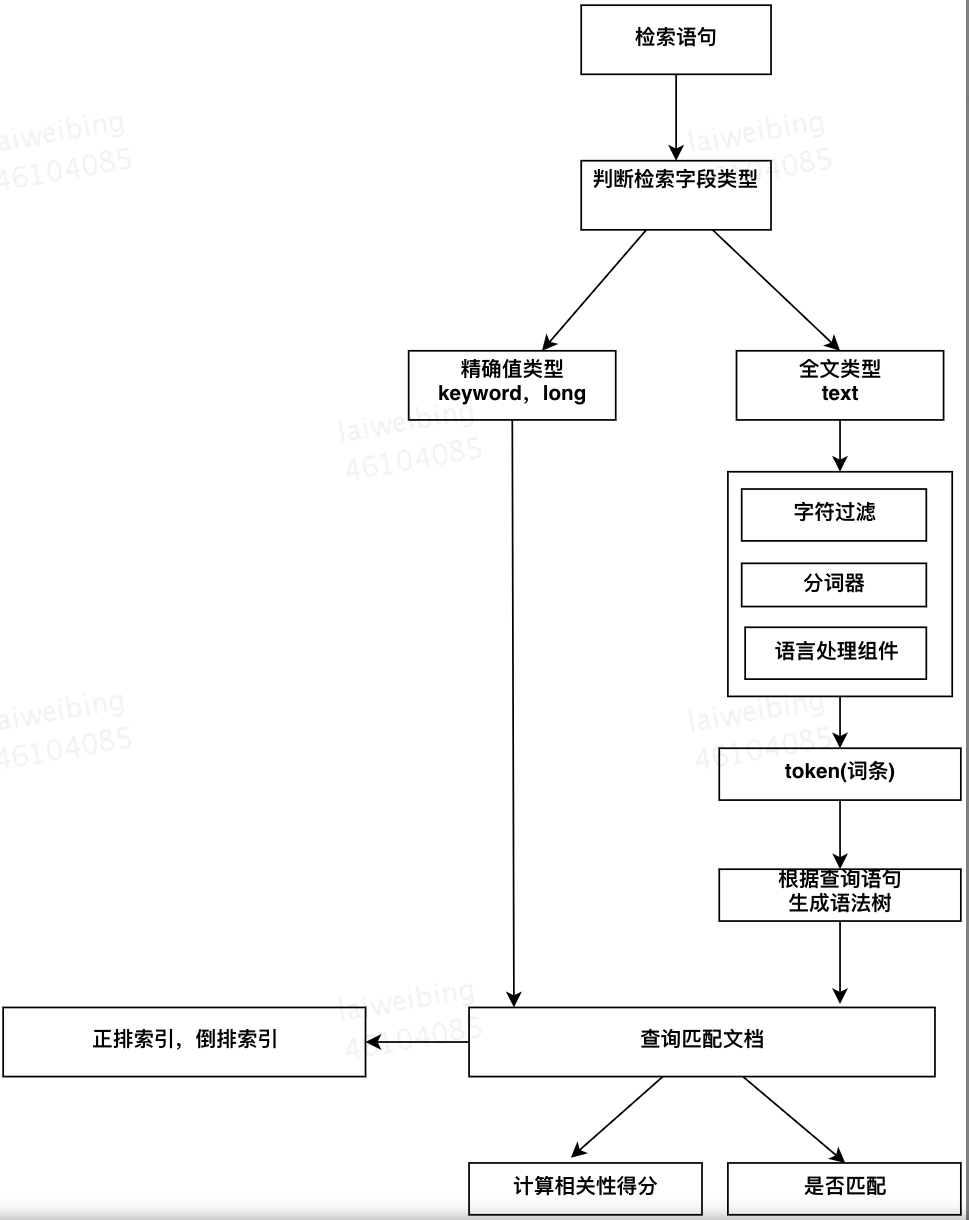
三、分布式搜索
上述讲了索引是如何建立以及数据是如何被检索的,下面看看,一个分布式集群中,用户发起一次检索请求,如何得到结果的
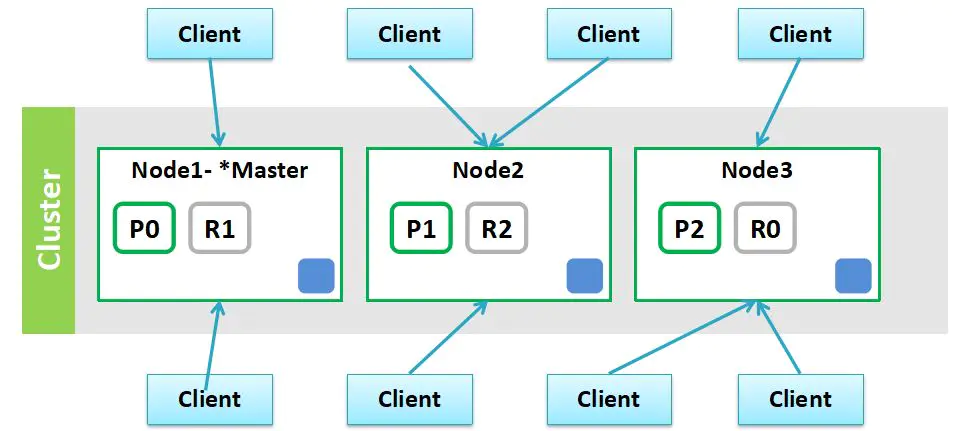
3.1 分布式集群组成
先看下一个集群的组成如下:一个集群有三个节点,集群上的索引有 3 个分片,每个分片有一个副本,
3.2 分片组成
如图,一个分片的主要组成如下
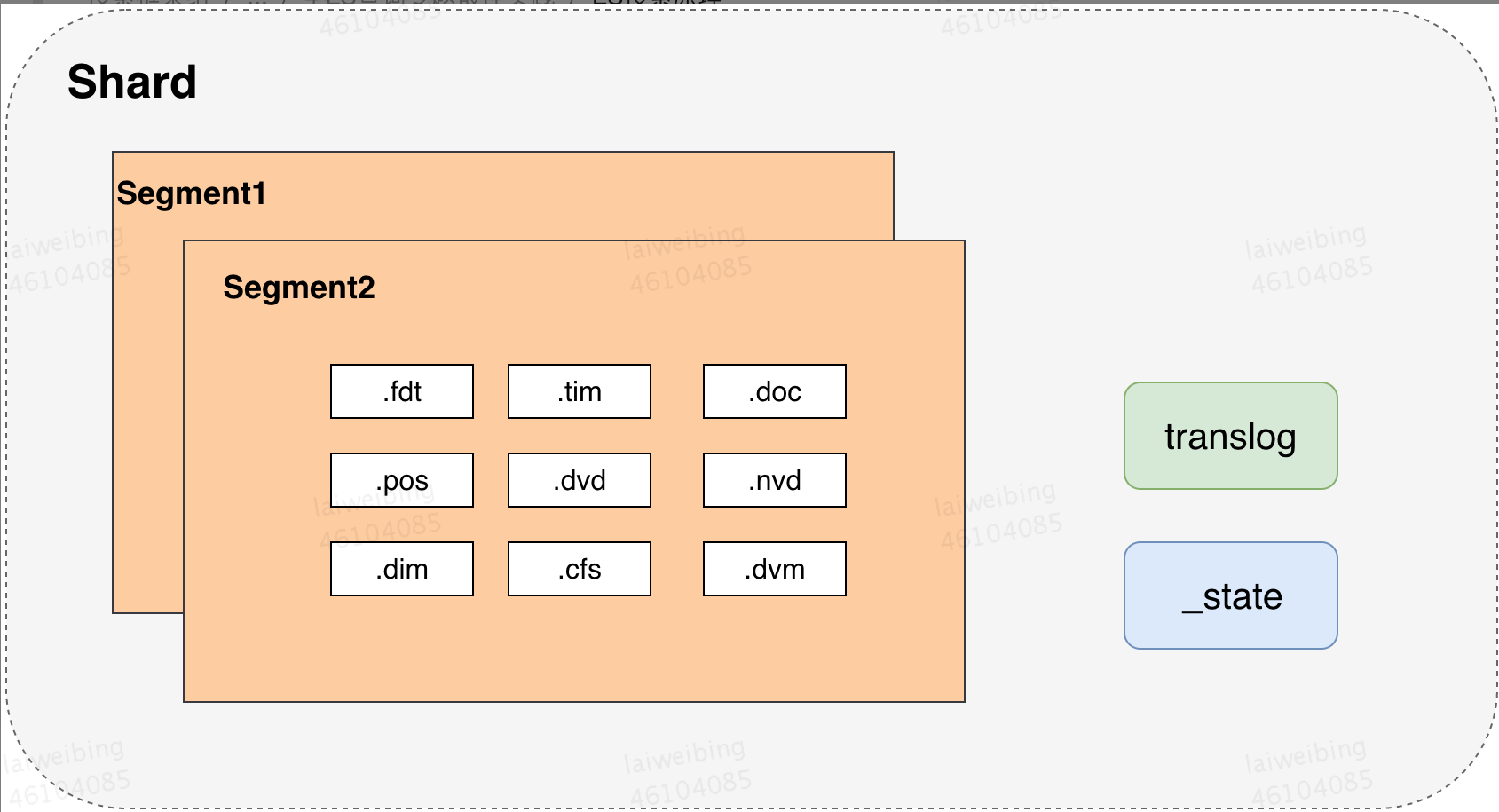
以一个 40G 索引为例子,如下:
| 文件类型 | 文件意义 | 磁盘占比 |
|---|---|---|
| .tim | 倒排索引的数据文件,索引具体内容,包含词项词典,存储术语信息 | 较大 3G |
| .tip | 倒排索引的索引文件 | 8M |
| .fdx | 正排存储文件的元数据信息 | 1.2M |
| .fdt | 存储了正排索引的数据,写入的原文件在这里 | 较大,1.5G |
| .pos | 全文索引的字段,会有该文件,保存了 term 在 doc 中的位置 | 800M |
| .dvd,.dvm | lucene 的 docvalues 文件,即数据的列式存储,用作聚合和排序 | 42M |
| .doc | 保存了每个 term 的 doc id 列表和 term 在 doc 中的词频 | 占比较大 300M |
| .nvd,.nvm | 文件保存索引字段加权数据 | 特别小 8M |
| segments_N | 保存了索引包含的多少段,每个段包含多少文档 | |
| .cfs | 在 segment 小的时候,segment 的所有文件内容都保存在 cfs 文件中,cfe 文件保存了 lucene 各文件在 cfs 文件的位置信息 |
最核心的文件
- fdx,fdt 存储正排索引数据,即 FiledData
| Doc | Terms(Address) |
|---|---|
| Doc1 | USA |
| Doc1 | CA |
| Doc1 | WestStreet |
| Doc2 | USA |
| Doc2 | LA |
| Doc3 | China |
| Doc3 | Jiangsu |
| Doc3 | Suzhou |
| Doc4 | China |
| Doc4 | Jiangsu |
| Doc4 | Nanjing |
- .dvd,.dvm 存储列文件,即 docValue,如下为一个列式存储结构
| Doc | Terms(Age) |
|---|---|
| Doc1 | 33 |
| Doc2 | 13 |
| Doc3 | 19 |
| Doc4 | 15 |
| Doc5 | 11 |
- tim,tip 存储倒排索引数据根据,结构如下:
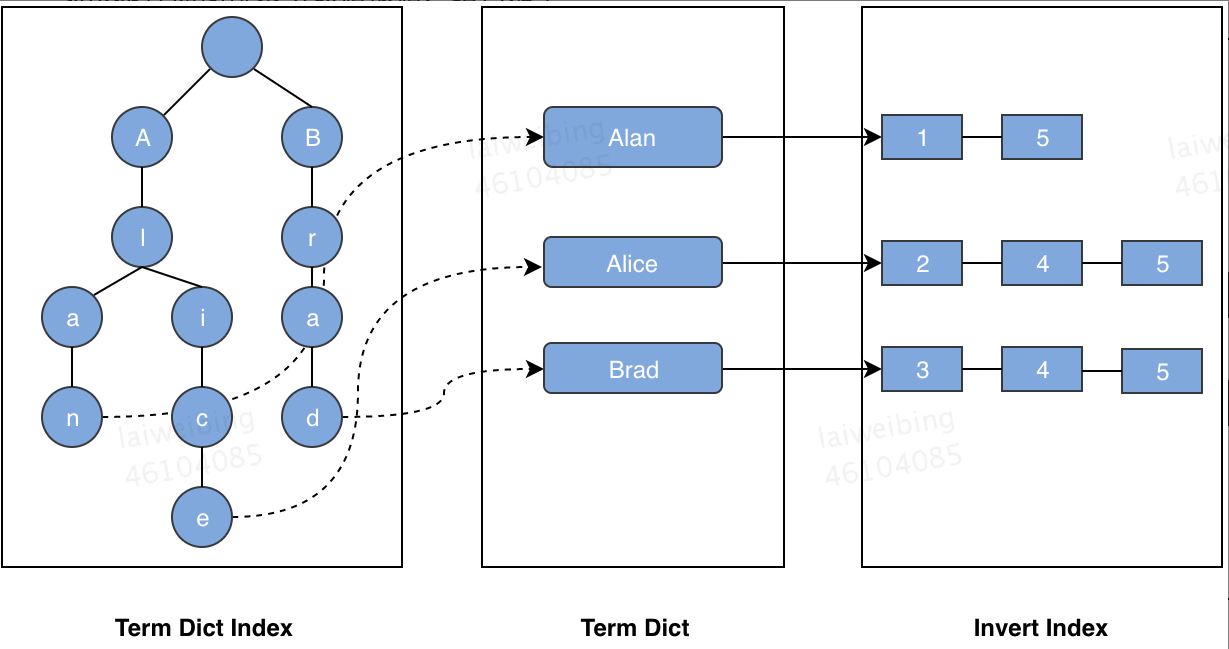
3.3 分布式搜索过程
默认 ES 的搜索过程分为两阶段 Query 阶段和 Fetch 阶段,当然还有 Query And Fetch 查询,两种方式优缺点如下:
3.3.1 query then fetch(默认的搜索方式)
如果你搜索时,没有指定搜索方式,就是使用的这种搜索方式。这种搜索方式,大概分两个步骤,第一步,先向所有的 shard 发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档 document),然后按照各分片返回的分数进行重新排序和排名,取前 size 个文档。
然后进行第二步,去相关的 shard 取 document。这种方式返回的 document 与用户要求的 size 是相等的。
- Query 阶段:得到目标结果对应的 doc Id 和排序信息,并且做聚合
- Fetch 阶段:根据 doc Id 列表查找对应的数据内容
3.3.2 query and fetch
向索引的所有分片(shard)都发出查询请求,各分片返回的时候把查询时指定的 size 元素文档(document)和计算后的排名信息一起返回。这种搜索方式是最快的。因为相比下面的几种搜索方式,这种查询方法只需要去 shard 查询一次。但是各个 shard 返回的结果的数量之和可能是用户要求的 size 的 n 倍。
3.3.3 搜索流程图
以下为 Query Then Fetch 流程图:
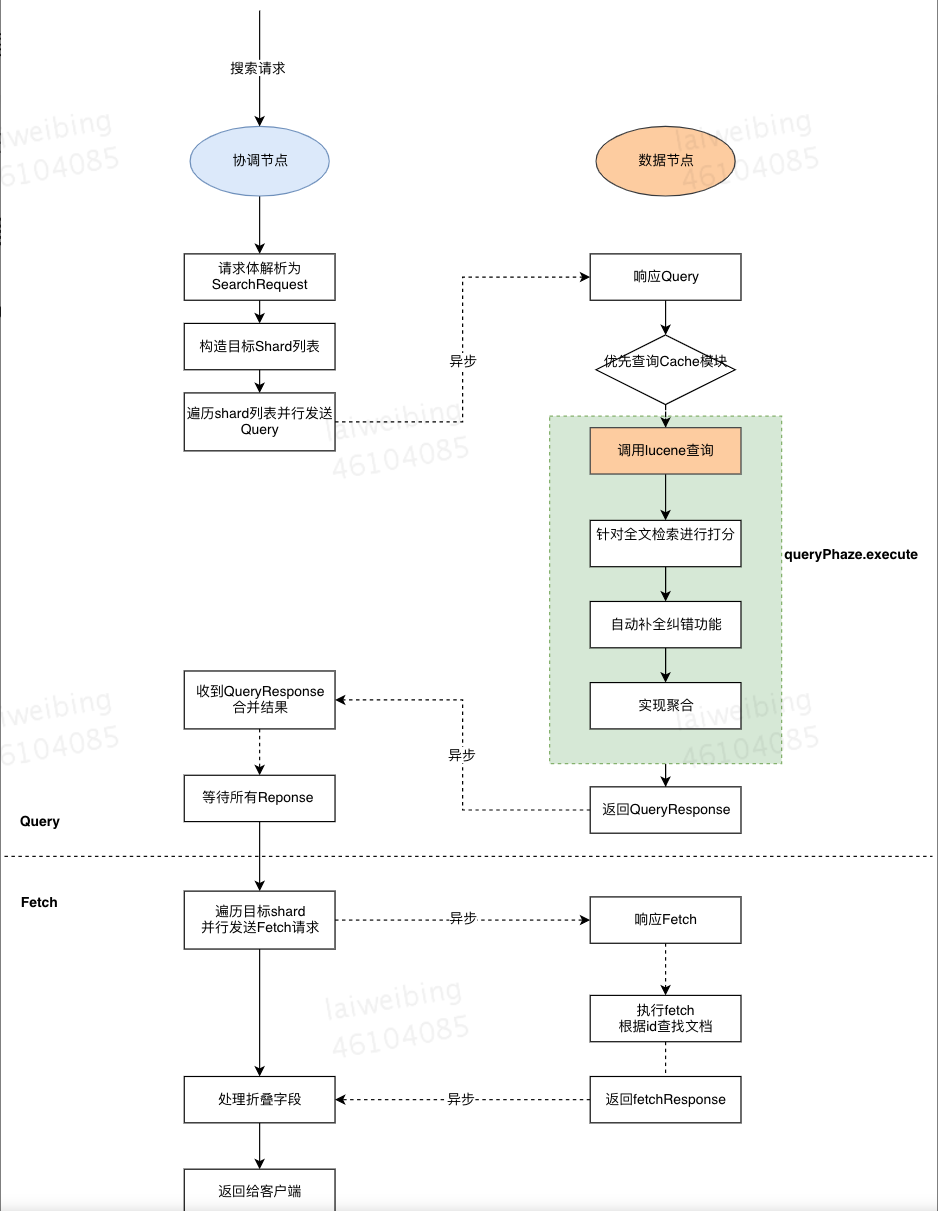
如上图,Query 阶段只是确定了要取哪些数据,但是并没有取具体的数据,Fetch 阶段才会去抓取具体的数据,最关键的一部调用 lucene 查询做了些什么呢?

四、ES 内存组成
我们看到 ES 查询会优先查询 Cache 模块,那 ES Cache 模块中到底有哪些数据呢?如图是 ES Heap 的主要组成部分,其中 Lucene 的段文件会存在堆外内存,所以 ES 节点建议 50% 的内存给 ES JVM,前提是不超过 32G,剩下 50% 留给 Lucene 作为堆外内存
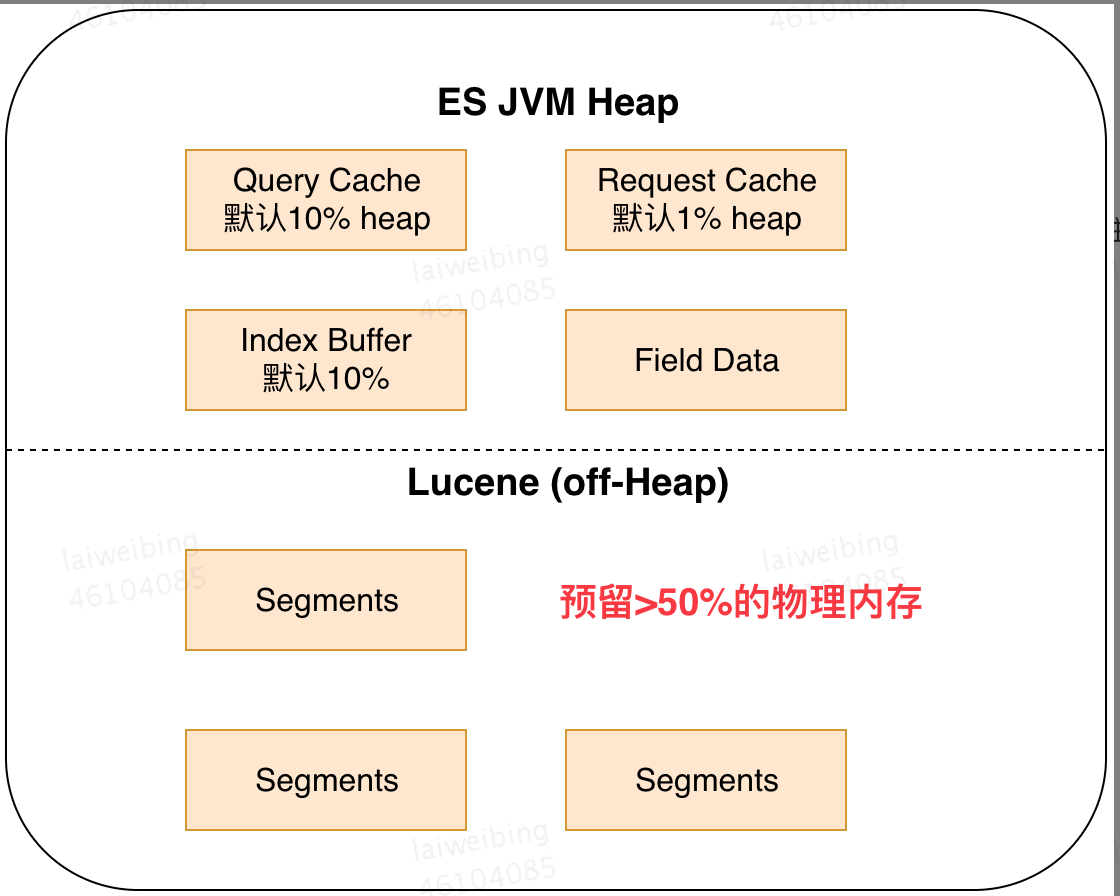
4.1 Query Cache(Filter Cache)
顾名思义,就是查询缓存,在 2.x 版本的 ES 中叫做 Filter Cache,就是使用 filter 过滤器进行查询的结果会被缓存在这里,常用的 terms,range 过滤器都会被缓存,说明如下:
- Query Cache 采用 LRU 缓存失效策略
- Query Cache 是节点级别的,每个节点上的所有分片共享一份缓存
- Query Cache 实际缓存的是 Bitset(位图),一个 Query clause 对应一个 Bitset
注意!缓存要生效,必须满足两个条件:
a)查询对应的 segments 所持有的文档数必须大于 10000
b)查询对应的 segments 所持有的文档数必须大于整个索引 size 的 3%
4.2 Request Cache
上述讲到的 QueryCache 是节点级别的,而这里 Request Cache 实际上分片级别的缓存,一次查询,会遍历多个多个节点上的分片,并且会在每个分片上执行查询,最终查询的结果会被汇总发送至协调节点,这里在分片上的结果集也会有被缓存,说明如下:
- 默认 Request Cache 是关闭的
- 目前只会缓存查询中参数 size=0 的请求,所以就不会缓存 hits 而是缓存 hits.total,aggregations 和 suggestions
- 每次索引 refresh 并且分片数据确实有改动,那 Request Cache 会自动失效
- 缓存的 Key 是整个 DSL 语句,只有 DSL 一样才能命中缓存
4.3 Index Buffer
这个理解起来简单些,主要在索引写入的时候需要,索引写入的时候不会直接写到磁盘,而是先写到 Index Buffer,当其满了或者 refresh/flush interval 到了,就会以 segment file 的形式写入到磁盘。
4.4 Field Data Cache
4.4.1 Field 的来源
先引用 ES 官网的一段话如下:
Search needs to answer the question “Which documents contain this term?”, while sorting and aggregations need to answer a different question: “What is the value of this field for this document?”.
Most fields can use index-time, on-disk doc_values for this data access pattern, but text fields do not support doc_values.
Instead, text fields use a query-time in-memory data structure called fielddata. This data structure is built on demand the first time that a field is used for aggregations, sorting, or in a script. It is built by reading the entire inverted index for each segment from disk, inverting the term ↔︎ document relationship, and storing the result in memory, in the JVM heap.
这里表达的意思:普通查询只需要知道目标文档在哪儿,而聚合或者排序查询还需要知道文档中某个字段的值是多少,对于部分词的字段,docValue 中会存储 docId_Value 的映射关系,这能满足聚合或排序,但是对于分词的字段(分词字段不支持 docValue),要实现这种字段和 Value 的缓存,便有了 Filed Data
4.4.2 Filed Data 结构
Field Data 也是 DocId–Term 的映射,如图,当我们需要对 age 做平均的时候,只需要遍历 docId,根据 docId 找到对应的 age,然后求个平均,效率会很高
| Document | age | salary |
|---|---|---|
| doc1 | 22 | 3232 |
| doc2 | 33 | 32323 |
| doc3 | 32 | 32323 |
4.4.3 Field Data 对比 Doc Value
Doc Value 和 Field Data 实现的功能一直,不过 doc_value 不支持 text 类型,并且 doc_valu 在索引创建的时候就已经生成好了,具体对比如下:
| 维度 | doc_values | fielddata |
|---|---|---|
| 创建时间 | index 时创建 | 使用时动态创建,默认不开启 |
| 创建位置 | 磁盘 | 内存(jvm heap) |
| 优点 | 不占用内存空间 | 不占用磁盘空间 |
| 缺点 | 索引速度稍低 | 文档很多时,动态创建开销比较大,而且占内存 |
4.5 Segment Memory
我们知道一个索引是由多个分片组成的,而一个分片又是由多个段文件组成的,一个段文件就是一个完整的倒排索引,倒排索引如果想要全部存储到内存里,这不太现实,太大了,但是 ES 为词典做了一层前缀索引,这个前缀索引默认会被加载到内存中,Lucene 的前缀索引使用 FST 来实现
4.5.1 FST 结构
- FST 全名:Finite Satae Transducer,实际上是一颗 TRIE 树,具体 TRIE 树的创建自行参考,这里不多讲
- FST 结构优点:存储空间小,所以可以被加载到内存,其次查询效率高,远高于 HashMap,Binary Tree 等数据结构,如下为一个 FST 数据结构参考
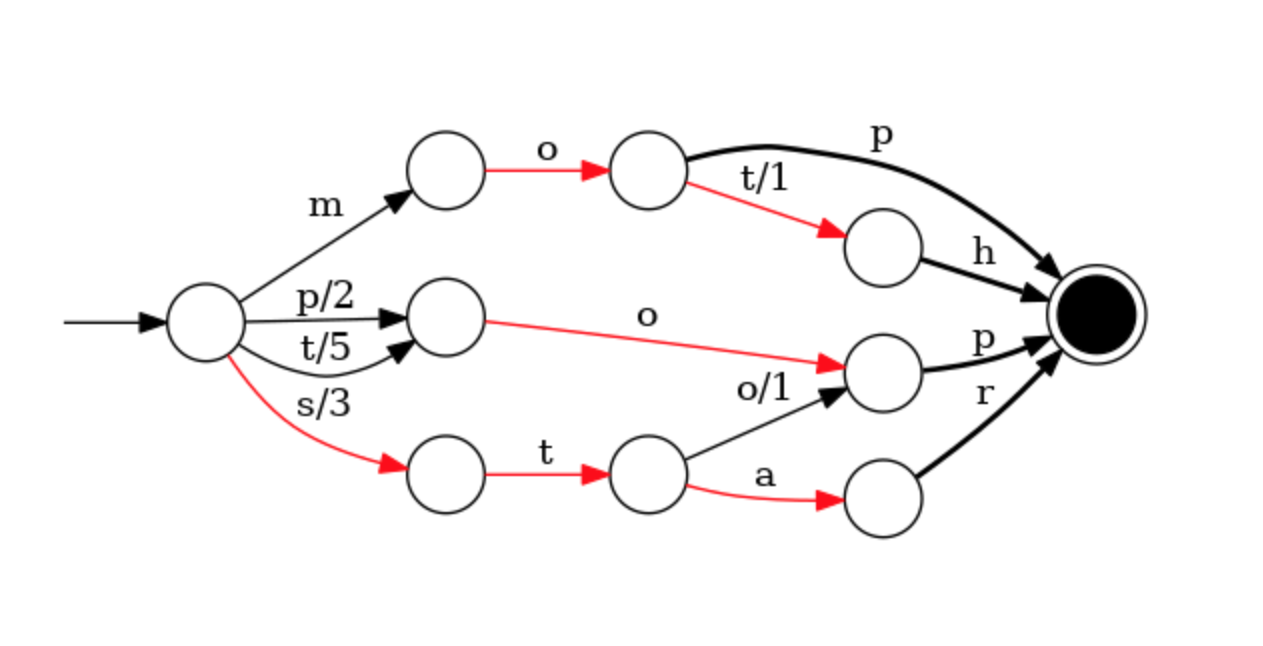
4.5.2 控制段文件数量
- 如上所说,每个段文件都会有 FST 前缀索引,这个索引会被存储到内存中,如果段文件越多,那么占用的内存越大,所以我们要定期合并段文件,同时集群的分片不能过多,因为分片越多,段文件也就越多了