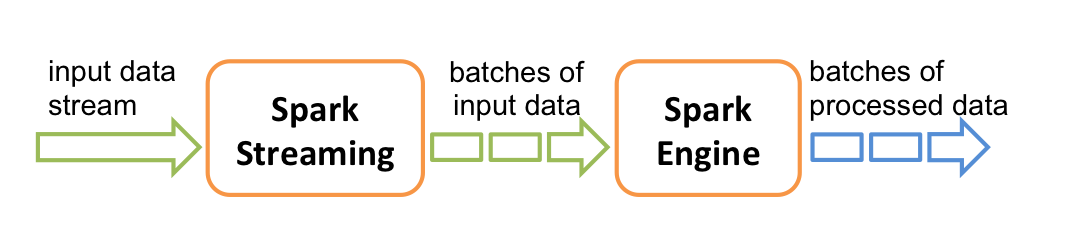
Java工程中内存管理总是一个绕不过去的知识模块,无论HBase、Flink还是Spark等,如果使用的JVM堆比较大同时对读写延迟等性能有较高要求,一般都会选择自己管理内存,而且一般都会选择使用部分堆外内存。HBase系统中有两块大的内存管理模块,一块是MemStore ,一块是BlockCache,这两块内存的管理在HBase的版本迭代过程中不断进行过各种优化,接下来笔者结合自己的理解,将这两个模块的内存管理迭代过程通过几篇文章梳理一遍,相信很多优化方案在各个系统中都有,举一反三,个人觉得对内核开发有很大的学习意义。本篇文章重点集中介绍MemStore内存管理优化。
基于跳表实现的MemStore基础模型
实现MemStore模型的数据结构是SkipList(跳表),跳表可以实现高效的查询\插入\删除操作,这些操作的期望复杂度都是O(logN)。另外,因为跳表本质上是由链表构成,所以理解和实现都更加简单。这是很多KV数据库(Redis、LevelDB等)使用跳表实现有序数据集合的两个主要原因。跳表数据结构不再赘述,网上有比较多的介绍,可以参考。
JDK原生自带的跳表实现目前只有ConcurrentSkipListMap(简称CSLM,注意:ConcurrentSkipListSet是基于ConcurrentSkipListMap实现的)。ConcurrentSkipListMap是JDK Map的一种实现,所以本质上是一种Map,不过这个Map中的元素是有序的。这个有序的保证就是通过跳表实现的。ConcurrentSkipListMap的结构如下图所示:

基于ConcurrentSkipListMap这样的基础数据结构,按照最简单的思路来看,如果写入一个KeyValue到MemStore中,肯定是如下的写入步骤:
在JVM堆中为KeyValue对象申请一块内存区域。
调用ConcurrentSkipListMap的put(K key, V value)方法将这个KeyValue对象作为参数传入。